读论文《In Search of an Understandable Consensus Algorithm》 --- raft (2)
前言
  在上一篇文章里面,介绍了raft定义的一些接口,leader和follower这些身份的一些特性。在下面的文章中,将继续讨论一下leader的选举的一些细节问题。
 
Leader election
什么时候需要选举?
  raft使用了心跳机制来判断是否发起一次leader election。下面来看一下,当集群启动的时候是如何发起第一次选举的。
  当server启动的时候,他是先处于follower状态的。如果server一直能收到来自master的心跳信号,那么就会一直保持在follower状态。
  leader会定期发送心跳信号,去跟集群中的其他server进行沟通,通过这样的机制能够有效地保持他们的身份(follower只要收到来自leader的心跳,就一直维持这种状态)。如果follower长时间没有收到这个心跳,那么follower就会认为,leader出现了事故。因此,集群需要选举出一个新的leader维持集群的正常运转。
 
选举的过程
  某个节点想要发起一次leader election,那么有以下事情需要他去完成。选举的过程如下:
(1)先给自己投票,并且把自身的currentTerm + 1
(2)并且把自身的状态设置为candidate
(2)然后并行地调用RequestVote RPC,向集群的节点请求投票,并且对回复进行一个统计
 
  以上,就是一次follower发起选举之后需要做的事情,上述这些事情做完之后,就开始等待下面事情发生(其中之一即可):
(a)RequestVote RPC统计后,获得过半选票后,赢得了选举
(b)收到别的follower发来的信息,声称它已经赢得了选举
(c)在规定时间内,该次选举(一般来说,以currentTerm来表示第几次选举)并没有成功选出一个leader,就再次发起一次新的选举
 
  情况a,当一个candidate获得过半的选票之后,它就会赢得该次选举,并且向集群中的所有其他机器发送自己赢得选举的信息。在介绍RequestVote RPC接口的时候简单介绍过,该接口会根据,来者优先的策略,去决定把票投给谁。并且在每次的选举中,每个节点只能投票给其中一人。(这种投票的策略保障了不会发生重复投票的情况,但是会带来一些其他的问题,放在后面讲)
  情况b,节点输掉选举。当某个candidate a 在等待选举结果的时候,收到来自别的candidate b发出的heartbeat信号,声称candidate b已经赢得了选举。如果该心跳信号的currentTerm大于等于candidate a的,那么就认为自己(candidate a)已经输掉了选举,转化为follower状态。
  情况c,就是在该currentTerm的选举过程中并没有任何一个candidate成功获得过半的选票,赢得选举。如果在同一时间内,太多follower失去跟leader的连接,成为candidate的话这种情况是有可能发生的。并且会带来大量的无用选举。因此,我们必须想办法减少这个问题发生的概率。
选举图示
选举算法其他的一些细节
  上面对raft的描述,已经大致讲清楚了,leade是怎么样选举出来的。但是实际上,该算法仍旧存在一些小问题。下面将讨论一下,会出现哪些事情,并且通过怎样的技巧去解决它们。
保证日志的持久性
  我们显然是希望,如果一条日志被leader提交了,即使是以后切换了新的leader,该条日志仍旧会存在于新的leader的日志集中。这显然是理所当然的事情,但是在上面的算法里,并不能做到这种保证,而是需要添加一些限制条件。
 
我们先来讨论一下,为什么上面讨论的算法,无法做到持久性的保证。如下图所示:
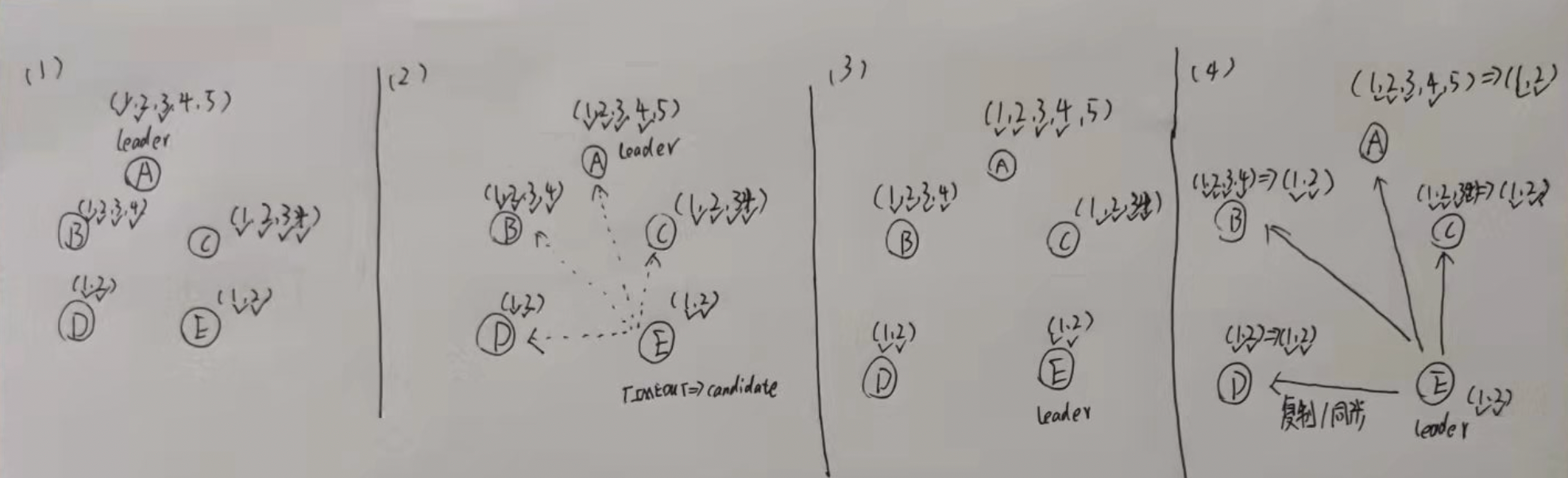
(1) 一个集群里面,所有节点的日志复制进度都不尽相同
(2) 此时一个比较落后的节点,率先超时,转变成candidate,并开始向集群其他节点申请票数
(3) 成功选举成为了leader,并开始新一轮的同步
(4) 因为,根据复制日志的规则,强制其他所有follower接收leader的日志,因此follower的日志被重写。造成了日志(3,4)的现象
  因此,为了解决这个问题,在原有的基础上面,还要再多加一个up - to - date规则。什么是up - to - date规则呢?其实很简单,在candidate调用getVotes RPC想要获取票数,需要额外多传递一些参数,就是candidate最新那条日志的Term和Index。
  有了这两个参数,follower就能判断,向“我”请求票数的candidate目前,它与原来的leader的进度 和 我跟leader之间的进度,到底谁比较快。如果candidate更快,就选择把票投给它,如果“我”更快,则拒绝投票。这就是up - to - date机制。
  为什么说这个机制能够保证日志的持久性呢?这我就不详细解释了,提示一下。在上一篇文章说过,如果一条日志被leader提交,那么绝大多数的节点必然已经提交该日志,再结合刚提到的up - to - date规则,答案就显而易见。
 
确信规则
  什么是确信规则呢?其实很直白,就是当follower确信自己没有与leader断开连接,或者说leader没有任何问题,仍旧存活。在种情况下,即使有candidate向其进行请求投票,follower都会拒绝该次投票。
  在我看来,这个规则相当重要,能够避免很多奇奇怪怪的事情发生。加上了这个限制规则之后,有两个好处,下面来说一下。
(1)避免没有意义的选举
  避免整个集群中,只有一个follower与leader断开连接。如果该follower发起一次选举,并且取得选举的胜利,成为了新的leader。这显然是非常不合理的,因为其他的follower与leader的连接都还好好的。这次选举,强行破坏了原有的关系,显然是没有任何实际意义的。
(2)避免奇怪的事情发生
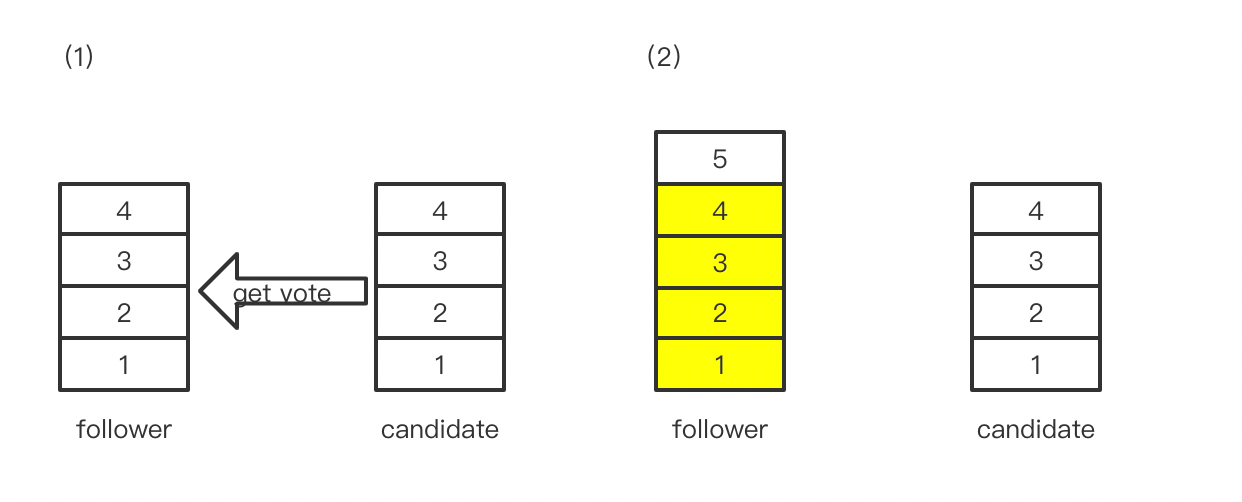
  如下图所示,在(1)的时候,candidate确实是符合up - to - date。但是follower与leader的连接仍旧存活,仍旧能接收到leader发来的日志,那么在(2)的时候,candidate就不是up - to -date了,如果此时它成为了leader那么就不能保证数据的持久性。
  如果,采用了确信规则,再加上majority rule。那么就能够确保,当这个集群,真的发生了大部分节点都无法取得与leader的联系时,才能成功选举出一个新的leader。并且这种选举,必然不会发现这样的数据丢失情况
 
避免分散票数的选举
  这个其实就很简单了。如果一段时间间隔内,follower节点没有收到来自leader的心跳信号,那么follower会转变为candidate。问题是,如果该时间间隔都是相同,那么就会出现,同一时间会有大量的candidate出现。造成选票被瓜分,无法出现一个节点赢得绝大部分选票。
  因此,为了解决这个问题,就是把该时间间隔在合理范围内,设置成随机值。这样就能大大避免,在某一个时刻出现大量的candidate。
 
避免脑裂发生
  脑裂是什么,相信有对分布式共识算法有一定了解都知道这个问题。那么raft是如何解决这个问题的?简单提示一下,具体我就不描述了。raft是通过赢得选举的Majority Rule,还有Term,以及Log Matching Property来避免脑裂。
 
Log replication
日志复制的流程
  一旦一个节点被选举成为leader,那么该节点就成为了集群的代表,去处理客户端的请求。我们知道,为了提高可用性,就需要备份master的数据到其他节点上面,raft中用到日志复制这个机制去达成备份数据的目的。下面,我们来讨论一下日志复制这个机制是怎么运作的,以及会遇到什么小问题。
  leader收到客户端请求后,会把请求命令,节点当前的term,还有日志的索引封装成了一个log entry,然后并行调用AppendEntries RPC,向集群中的其他节点追加这条log entry。当leader确认日志已经成功复制到其他节点上面后(这点很重要,后面细说),leader就会把日志提交(committed),然后把它日志的命令添加到自己的状态机里面,然后再把客户端请求的结果回复给到客户端。
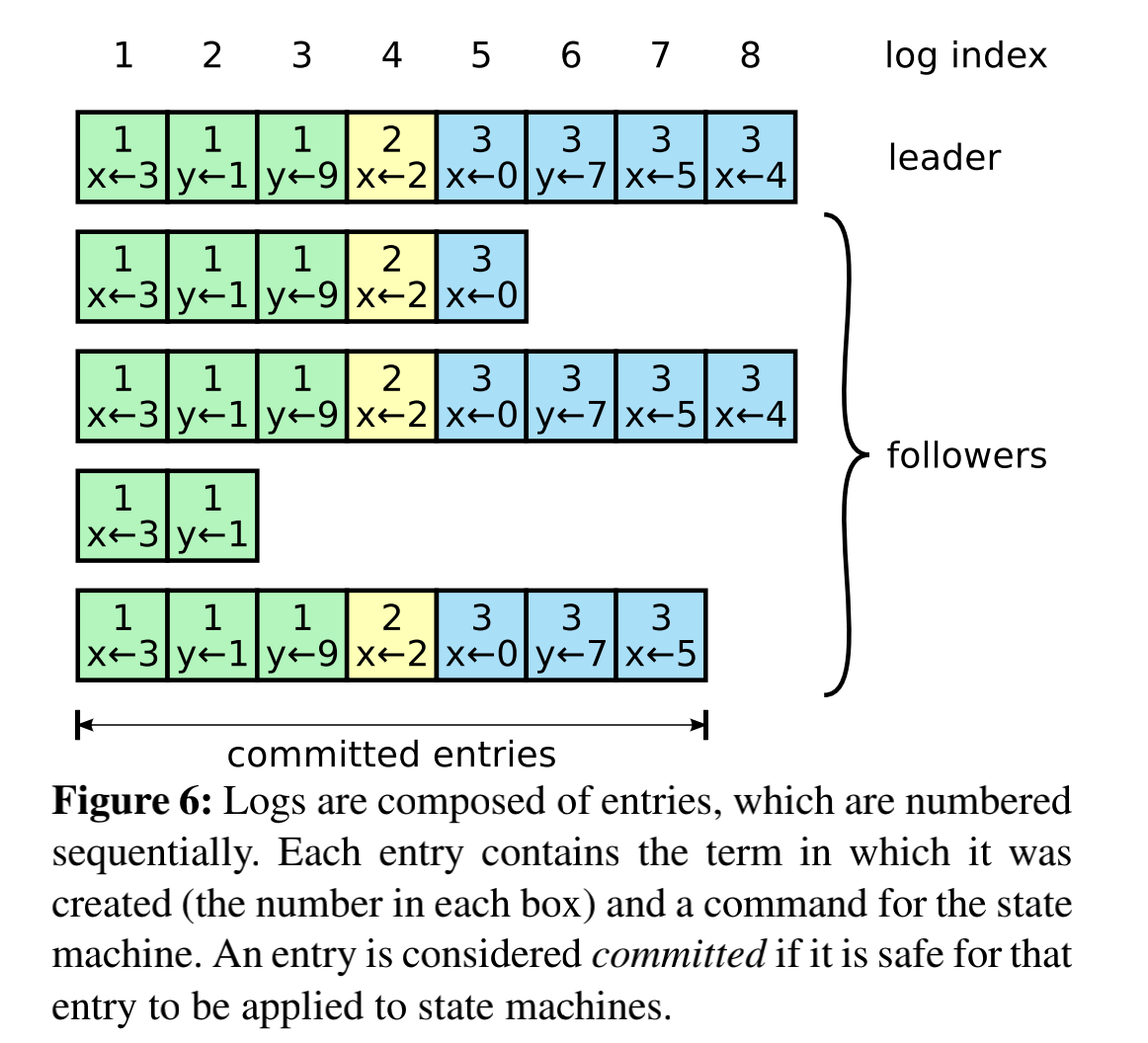
  logs entry如上图一样在集群中排列,在上面的描述中已经说过了,log entry中包括了 客户端请求的命令,term(该日志是哪个时期的leade发出的),还有索引(用来定位该log entry在日志中的位置)。
  日志里面的term number是用来校验follower和leader之间的日志不一致的问题,并且还用来实现之前在part-1文章中说过的几个raft提供的保证,下面来回顾一下:
- Log Matching Property:如果集群中的两条日志具有相同的
index 和 term,那么这两条日志就是相同的。 - Leader Completeness Property:如果日志被
leader提交了,那么这条日志一定会出现在以后leader中的日志里面。
leader commit 机制
  leader收到一次客户端请求之后,leader就会调用追加日志的接口把日志追加到其他节点上面。但是这时候,leader只是把日志缓存起来。但是其他follower节点会直接把日志进行提交。等到一个合适且安全的时候,才会把该日志进行提交(commit)。
  leader想要追加一个log entry到集群的其他节点,会调用追加日志的接口,当过半的follower成功地把该log entry提交到自己的日志集后。leader就会认为该log entry可以被安全地提交。
  这个机制,保证了集群节点之间日志的高一致性。而且通过该机制实现了raft保证的Log Matching Property。这个保证主要是两个内容,下面来讨论一下这个:
1.集群中的两条日志记录,如果具有相同的Index和Term,那么就是该日志记录就存储着同一条命令
  来分析一下。每一次选举的发生,都会有一个属于该次选举的Term,当选出leader之后,leader就会使用该Term。也就是说,一个Term只有一个leader。
  所以,不同Term的Log Entry是不同由不同的Leader发出的,所以必然是不同的日志记录。那么相同Term的日志记录,必然是同一个leader发出的。
  日志索引(Index),表示该记录在日志集的位置。那么两条日志,具有相同的Term 和 Index,就是说明该日志记录的本源是在同一个leader日志集里面的,同一个位置。因此,就是具有同样的命令。
2.如果不同节点中的两条日志,具有相同的Index和Term。那么这两个节点的日志集里,在该日志记录前的所有记录,都是一致的
  这个保证是如何实现的?还要结合上面的保证来分析。
  上面说到相同Term 和 Index的日志记录,实际上是同一条记录。根据AppendEntries RPC它的请求参数包括,leader即将要追加到follower节点的记录(Current Log Entry)的前一条记录(Pre Log Entry)。
  如果Pre Log Entry在follower节点中存在 / 匹配,那么才会在Pre Log Entry后面追加Current Log Entry。否则,就会尝试去先把Pre Log Entry追加到follower上面。如果还不匹配,就继续尝试追加上一条日志记录,直到找到该follower和leader日志集中,Index最大的那条匹配记录。
  结果就是,当一条日志成功追加到follower上,那么leader就会知道,该日志前的所有记录,跟leader都是一致的。
leader crash 机制
数据不一致
  正常情况下,上述操作能够保证leader和follower之间的一致。
  但是,如果发生了宕机,重新开启了一次选举,那么就很可能会发生数据不一致 / 脏数据的情况。下面,就简单什么时候会发生这些,以及raft是通过怎么样的机制去避免这些。
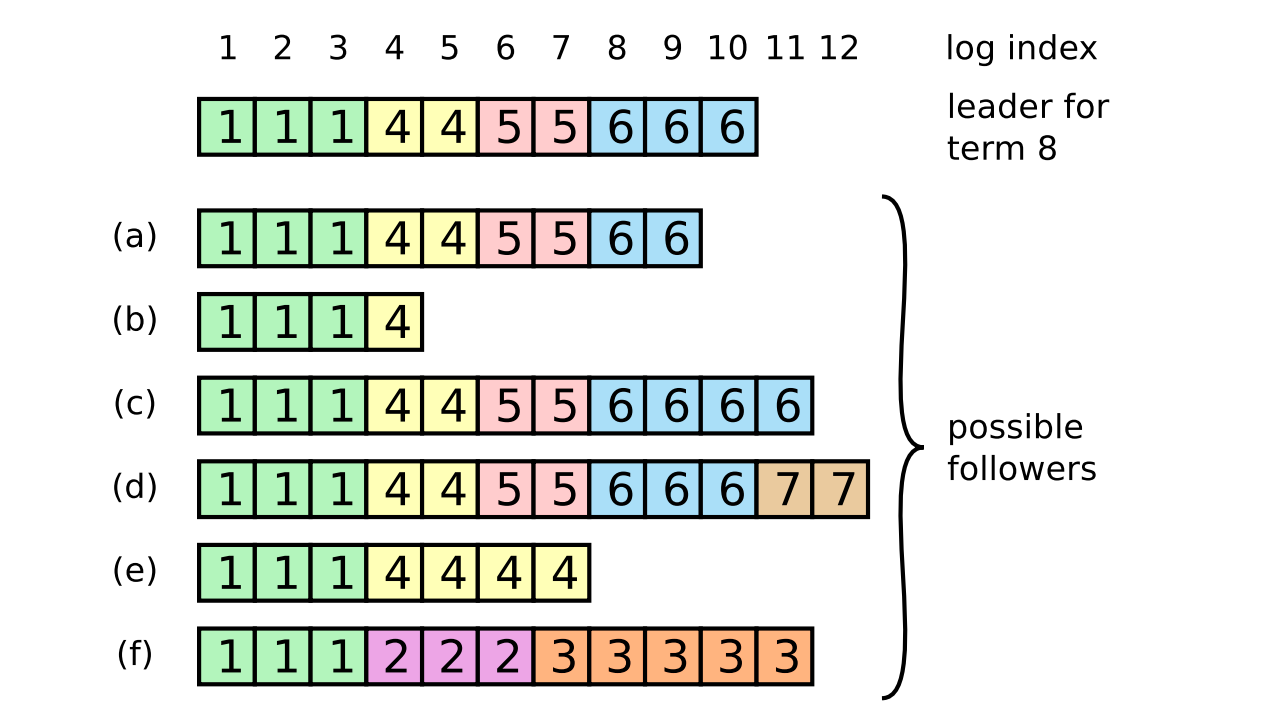
  比如说,当选举发生了,选举出了新leader。根据赢得选举的规则,我们知道该new leader必然赢得过半的选票。但是在极端情况下,小部分的节点仍旧会与old leader进行连接,此时集群中会存在有两个leader(实际上这不是脑裂,old leader节点的日志必然不会提交,因为无法获得过半的提交成功)。但是小部分的follower仍旧会接收old leader发出的日志记录,这就会造成数据不一致。
  就像是上面图中的(e)~(f)都是因为收到old leader发出的日志记录,产生的数据不一致的情况。详细情况我就不细说了,可以自己分析一下便知道。
修复不一致
  如何修复这些日志记录不一致的情况,leader强迫所有follower去接收它的日志,以leader的为准。这就意味着follower接收的脏记录将要被重写。
  其实这个机制的实现在上面就已经说过了,通过两个机制up - to -date 和Log Matching Property就可以保证。
up - to - date:保证了,已经被leader提交的记录,不会丢。Log Matching Property:这个机制负责找到Index最大的匹配记录,脏记录 / 不一致的记录
结尾
  好了,leader选举和日志复制的内容和细节都梳理得差不多。相信都能对raft有更进一步的理解。下一篇文章(如果有的话),会谈一下raft是如何更新配置的
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!