读论文《In Search of an Understandable Consensus Algorithm》 --- raft (1)
前言
  最近读了raft共识算法的论文,对其有更深且进一步的理解。raft是一种用来管理复制日志的一致性共识算法。它的作用跟Paxos相同,并且效率差距也不大。但是,raft最大的特点就是容易理解。这才得以让raft在工程实践里面,大规模应用。
  按照我个人的理解,让一个集群里面的服务器保持一致性或者说达成某种共识,实质上就是让log/command在所有服务器上都按照同一种顺序被执行。raft为了简化这个设计,参考了gfs选出了一个master,让其他所有服务器都服从master的执行顺序。
  为了减少复杂性,raft把一致性共识的关键leader选举,日志复制,安全性,集群配置更新,这几部分分割开来。下面的篇幅我们来讨论一下算法的种种细节
一致性共识算法
规则
  raft是如何实现一致性共识的?它是通过选举出一个leader,然后让其负责协调集群的日志复制工作。当其他的follower收到日志之后,便可以在合适的时机,把log里面的command作用到自己的状态机里面。
  上面已经提到过了,跟gfs一样,让一个master协调日志的顺序,这样做会简化很多设计(不然的话要加很多复杂的措施)。显然,在分布式的系统当中不得不考虑系统的容错性还有网络等问题,这些因素都会造成该集群中leader不可通信的情况。为了集群的高可用性,这时候就必须选举出一个新的leader。
  为了达成共识,需要遵守一些规则进行的。
state

这里的状态是所有在集群里面的server都要有的
- currentTerm:这里是server存储,目前它已知的最新的term
- voteFor:当选举发生时,
candidate向所有人请求投票,这个标记着投票给哪个candidate - **log[ ]**:就是log-entry,里面的内容包括该条日志包含的command和term(标记该log在哪个term里main生成)还有logIndex(一般情况,这是一个单调递增的)

这里的标识是用来协调日志的:
- commitIndex:服务器缓存日志的记录,标记该server已经缓存到了哪条日志,有了该标识方便master发送下一条log
- lastApplied:标记着最新一条应用到状态机的index

用来维护该发送哪条日志的
nextIndex[ ]:
nextIndex[i]表示,要发送给follower(i)的下一条日志,初始化的值是leader最新的日志+1matchIndex[ ]:
matchIndex[i]表示,已经复制到follower(i)的日志,初始值是0,单调递增
AppendEntried RPC
  这是一个RPC接口,被master调用,用来向follower进行日志的复制,还有进行heart beat。

这里是该函数的入参
- term:调用RPC接口时,会把leader目前的term传过去
- leaderId:我也不知道干啥的…后面论文中好像也没看到具体的应用
- prevLogIndex,prevLogTerm:leader追加的该条日志的上一条日志**(下面统一叫prevLog)他的lndex还有term。这里是为了实现
Log Complete Property** - **entries[ ]**:跟上面的logEntries[ ]一样
- leaderCommit:目前leader最新的commit-index
函数的返回值:
- term:每次Leader和follower进行交互的时候,都会比较他们的term,这样就能方便互相都能及时进行更新
- success:表示追加是否成功,这里不想解释了看上面的英文吧

该接口的一些细节:
(1)如果 当前server的term大于leader的term(该leader可能是以前的leader),那么显然就该拒绝这次追加请求
(2)如果 当前server的日志里面没有包含leader的prevLog,那么就拒接这次追求请求,并让leader把logIndex-1再进行重试。这样是为了在日志的序列里面找到,follower是从哪条日志开始与leader不一致的。这个机制保证了,Log Complete Property
(3)如果 追加日志时发生了冲突了,通常情况是同一个Index但是Term不一样,代表其中必然有一个是old leader产生的。因此,要删除old leader产生的还有该日志后面的日志
(4)follower追加没有缓存的记录,只有prevLog有包含
(5)这里没想明白为啥要做这个 leader和follower commitIndex的判断,到时候再看看
RequestVote RPC
  这是一个Candidate调用的接口,用来收集选票来达成leader的选举

接口函数的入参:
- term:candidate的term,用来辨别是否要响应该投票
- candidateId:记录投票给谁,对用
voteFor - lastLogIndex,lastLogTerm:candidate最新的log,这个是作用
update - to - date机制的,是决定是否投票的限制
接口的返回值:
- term:在RPC交互之后,用来更新
term的 - voteGranted:表示调用的
candidate是否得到选票

接口得到一些细节:
(1)跟上面的差不多,这里是为了比较是否是old term,如果是就要拒绝该请求
(2)如果该follower还没有投票,并且candidate的最新日志比该follower的要大,就证明candidate比follower更加up - to -date,这样把票投给它
(3)其实不仅如此,还有一个限制。有时候只有一个follower断开了和leader的连接,这时候该follower会成为candidate并发起一次选举。但是别的follower都没有问题。所以,只要别的follower确认leader还在存活,就拒绝该次投票请求。
Rule for server

(1)是把缓存的log / command添加到状态机的规则,lastApplied表示最新添加到状态机的日志索引,只要缓存索引 > 已经添加的索引,就表示可以继续该过程(add log to state machine)
(2)如果,收到一个RPC request,该请求中所携带的term比自身服务器记录的term还要大,则证明该服务器可能错过了某些时候的选举过程,因此需要重新设置term还有回到follower状态(如果服务器先前是leader)

(1)follower只会回复来自他们两个的rpc请求,并且follower不会主动调用请求。
(2)如果某个follower长时间没有收到来自leader的heartbeat,那么follower就会转变成candidate发起一次选举,等待成为leader

(1)leader由选举产生,当选出一个leader之后,要发出一个heartbeat来向集群传递,新的leader已经出来了。
(2)客户端的命令会先转发给leader,然后leader缓存该客户端请求到自己的local log,等到该请求应用到了state machine里面时,便会回复给到客户端。 (这里这个过程其实还有一点限制,下民的篇幅在展开细说)
(3)在向follower同步日志的过程里面,如果最新的日志索引 > 要给follower发送的下个日志的索引,那么就发送日志。**如果向follower追加日志失败,证明prvLog并不匹配,因此master会把nextIdx -1 然后重试追加日志的过程。
(4)如果存在一条日志索引N,N大于leader的commitIndex,且该日志索引N已经存储在大部分服务器上面。那么leader把其commitIndex设置为N。 (如果加了某个限制条件之后,该情况久不会发生,下面有讲解)
Five basic properties

(1)选举安全性质:每在一个term中,只有一个leader能够被选出来
(2)只有leader能追加日志:不解释了
(3)日志比较规则:如果两条日志它们的term和index都是一样的话,那么它们就是同一条日志
(4)日志完整性:如果leader中的某条日志已经提交到了某个follower上,那么该条日志前面的所有日志都已经被提交到了follower上,不会出现日志空洞,缺失日志的情况(除非是磁盘问题)
(5)状态机的安全:先不解释,后面会细说
Raft Basic
奇数节点
  在一个raft集群中,有一个很重要的原则就是,集群里面的节点个数必须是基数的,通常情况采用的是3 / 5。 因为只有奇数才能达成majority,偶数就没有这种效果,因为可能出现五五开的场景。
  在通常情况下,当一个决策(日志的提交,选举leader),只要该决策被大部分的节点承认,那么就可以把结果返回给外界。采用了这种majority的机制,有以下的好处:
- 首先,从性能的角度来看,这种
majority显然要不等待所有节点同步要高 - 其次,因为有
majority,这样能够保证在相邻的两次决策,必然存在一个节点都commit了两次决策。
节点的三种状态
  集群的所有节点只处于以下三种状态之一:Follower,Candidate,Leader。并且正常的情况下,只会有一个Leader,并且其他剩余的节点是Follower。
  在这之中,Leader负责处理所有的客户端请求;Follower只会被动地执行Leader 或 Candidate的rpc请求,并不会自己主动地去做一些其他的事情;Candidate,当某个Follower觉得集群可能出现问题的时候,就会转变进入该状态,发起一次选举,保证系统的正常运转。
下面是,集群的状态机转换,有几个特别的点我们需要注意:
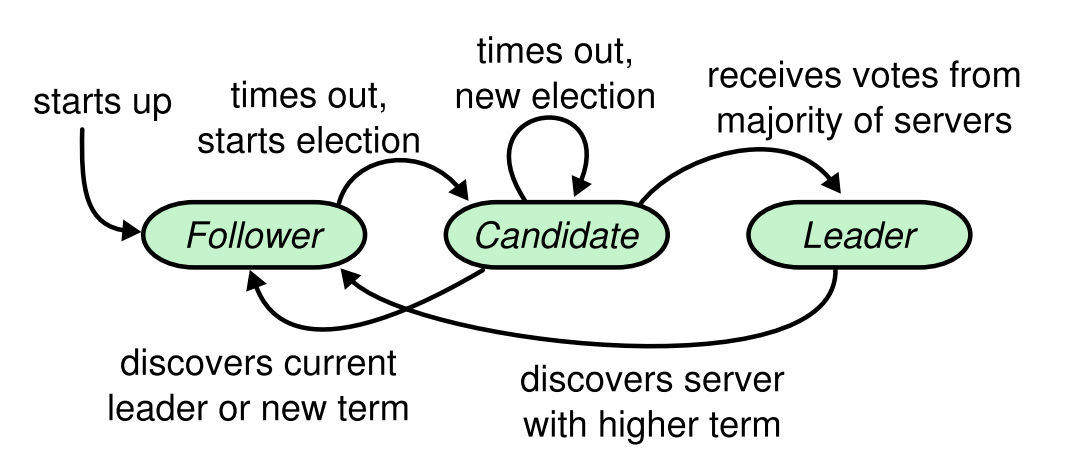
Follower只会在超时的情况下转变状态,进入Candidate。Candidate在一次选举中,获得大部分选票,就会成为新的Leader。Candidate在发现一个大于自己的Term或者是一条声明(某个节点赢得了选举,成为了Leader),则进入Follower状态。Leader只有在收到一个更大的Term才会转变状态,变为Follower。
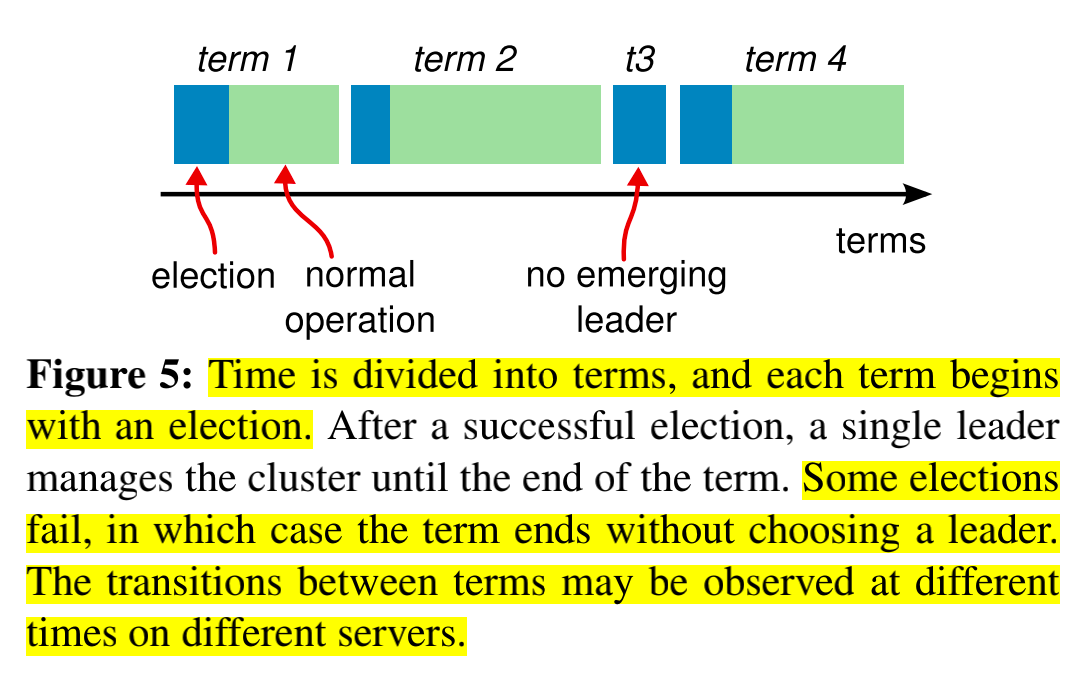
Term
  term是一个逻辑上单调递增的序列,并且该序列是与Leader election捆绑在一起的,是用来标记着该Leader是由第几次选举产生的。
  每一次Leader election都会产生一个term,在一次选举中可能会有一个或多个候选人,若是一次选举中某个节点成为了Leader,那么就会用该次选举的term作为ConcurrentTerm,去发送heartbeat让剩余的节点重新成为Follower。
  但是,一次选举中可能会出现多个候选人,很可能会出现票数被多个候选者平均掉了,因此会出现没有任何一个节点能够获得大部分的票数。那么这种情况,要怎么进行处理呢?继续用该Term发起一次选举吗?
  在Raft中,允许某次选举中没有选出Leader。当一次选举因为票数分散导致选举不出一个Leader,它会把term + 1然后重新发起一次选举。在论文中,作者并没有说明为什么要这样做,但是我猜测Raft的设计者是这样考虑的,如果一次再发起一次选举,仍就是使用上一次选举的term的话,那么就无法再次收获票数了。因为Follower已经记录了在该Term的选举中投过票了。
  由于篇幅问题,这篇文章就先介绍这些内容。关于Leader election和log replicate的内容放在下一篇文章
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!