如何保证缓存和数据库双写一致
  最近工作上用到了缓存。用缓存的时候leader让我注意一致性的问题。在调研一下公司常见的双写一致方案,发现大部分方案都不是完美了(虽然我个人觉得不少方案,其实还是有优化的空间的),需要结合实际的使用场景来选择,还是应了那句话不要抛开场景去谈技术选型。
  先说结论:因为写入数据看和写入缓存,是两个原子性操作(合在一起就不是了)。因此,所有方法只能尽量避免数据的不一致,总会在极端的情况下有数据不一的情况发生,要想完全避免这事,那只能依靠事务了。
常用的解决数据不一致的方案
先来简单了解一下,三种比较常见解决“缓存-数据库一致性”的方案。
缓存旁路模式
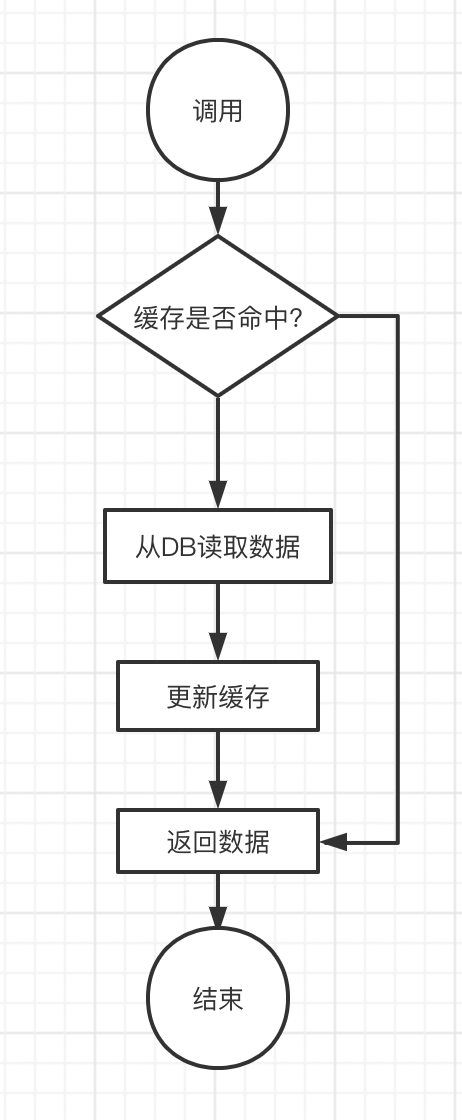
  缓存旁路模式,是最常用的保证双写一致的模式,对于数据的读取和更新有两种不同的流程。
对于读取数据:
1 | |
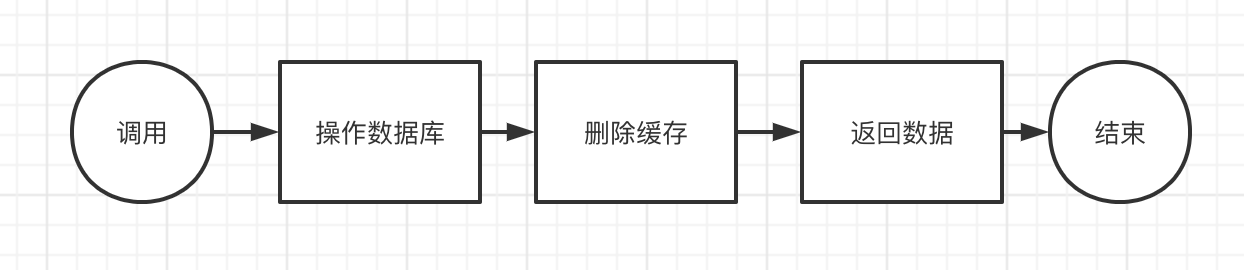
对于写数据(插入/更新):
  写流程就简单一些了,只需要插入的时候,先操作数据库,然后再删除缓存就好了。
读写穿透
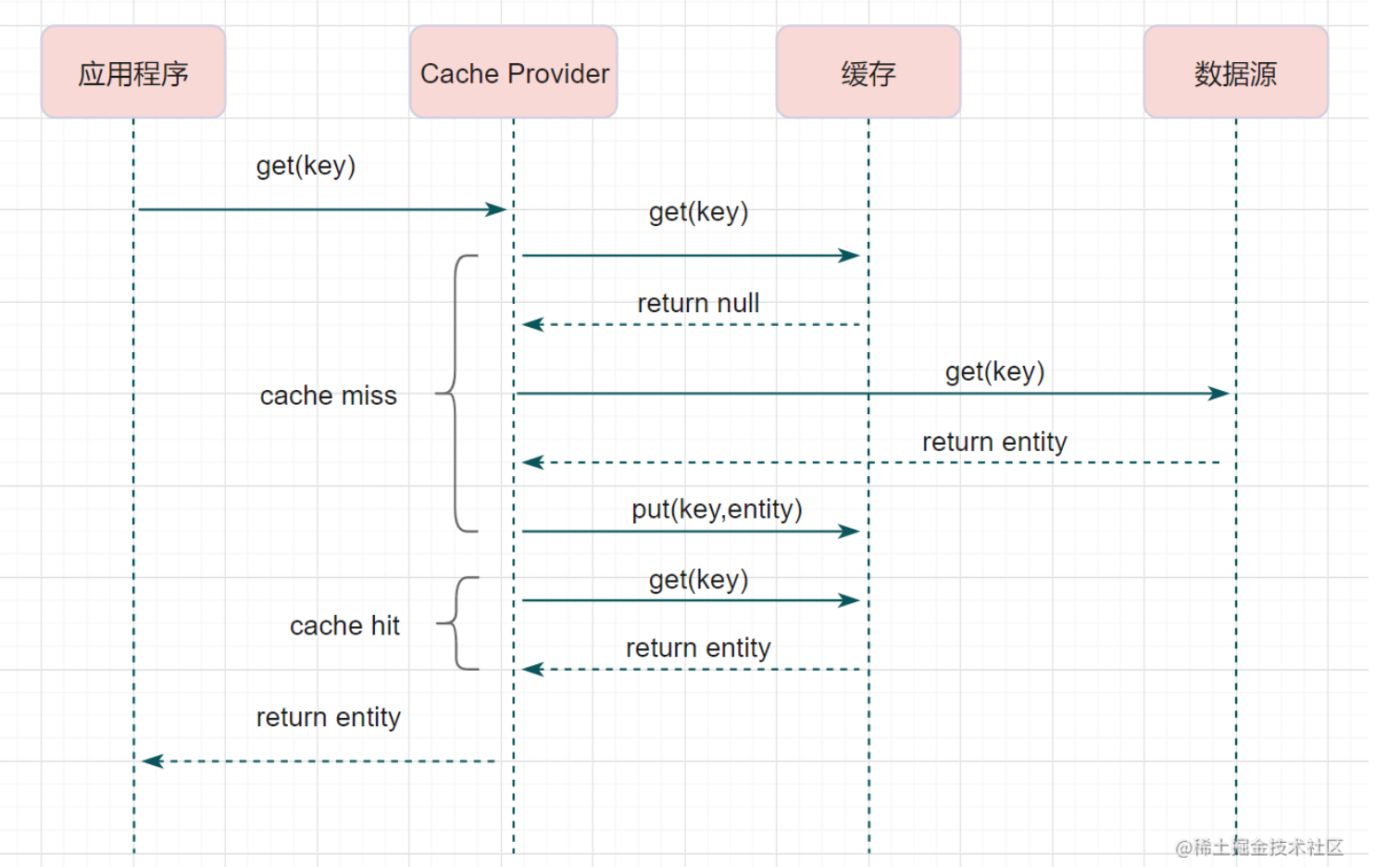
  这里他只是把缓存作为主要的存储单位,抽象了一个chache provider服务,该服务负责缓存的存储,以及后续与数据库的交互交给缓存去进行处理,这对客户端来说是不感知的,看起来只是简单地调用了一下缓存。
读流程
- 从缓存中读取
- 如果缓存命中,返回结果给调用者
- 如果缓存不命中,则缓存发送请求,到数据库中请求数据,然后缓存再返回给调用者
写流程
- 缓存命中,则更新缓存,然后缓存同步去更新数据库
- 缓存没有命中,则直接更新数据库
这个解决方案,很多地方都跟CAP一致,但是最大的不同点在于读写传统在更新的最后没有对缓存中的记录进行删除。这个我个人觉得有一些问题,后面的篇幅再细说。
异步缓存写入
  这个方案,跟读写穿透很像,两者都是通过抽象的cache provider服务,对db进行交互。
  但是又有很大的不同,读写穿透或者是缓存旁路,都是同步地对数据库进行更新,而该方案则不直接更新数据库,而是批量去更新数据库。
  这跟kafka一样,带来的吞吐率的提升,但是带来的一些一致性问题。
要考虑的问题
Q:删除缓存,还是更新缓存
  目前为止,大家都比较不喜欢更新缓存的方案,因为在高并发的场景之下,很容易出现数据不一致的问题的问题。我们假设是在“先更新db,再更新缓存”的方式下进行双写看看会发生什么样的问题。
  假设,现在有两个请求要对同一个记录进行更新。我们希望db和cache这两个收到记录更新的顺序是一致的(比如说,都是先收到请求1再收到请求2,或者先收到请求2再收到请求1),但是因为网络等其他原因,最后的顺序很可能跟我们理想情况不太一样,如下图:
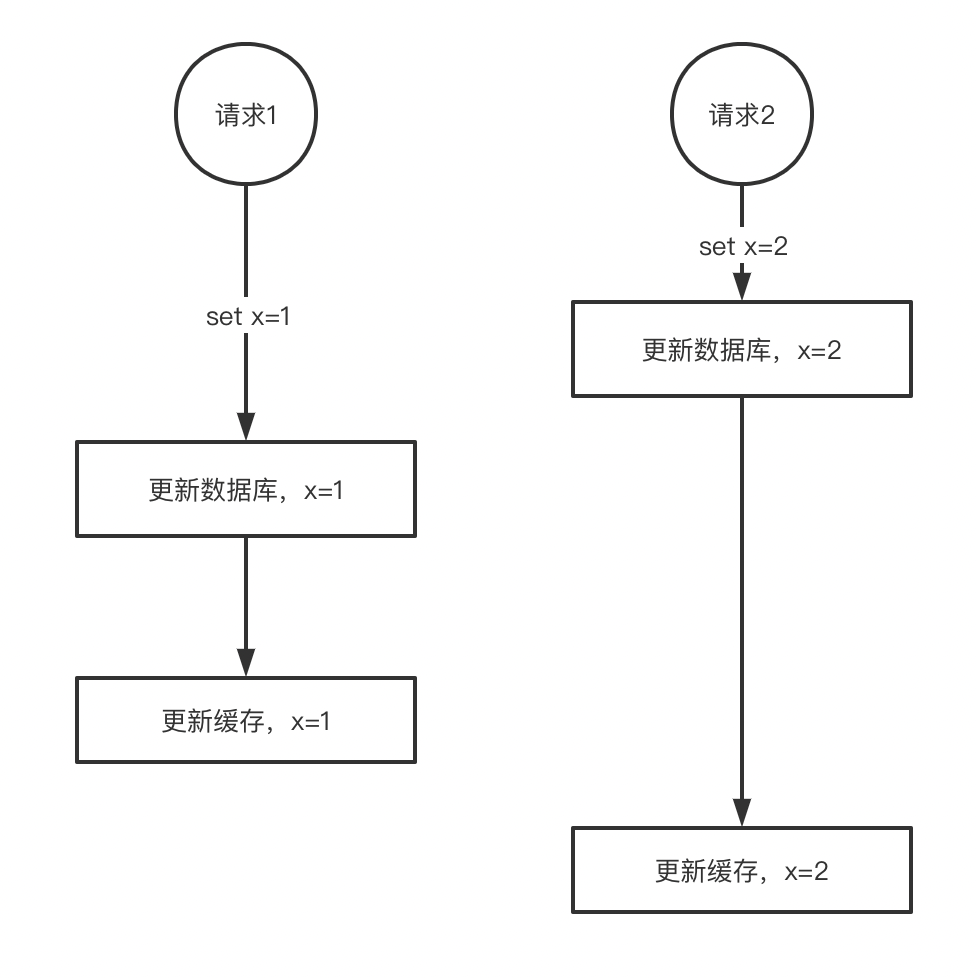
  从图片中我们可以看到,因为db和cache他们收到请求的顺序不一样,因此造成了最后db中的数据是1,cache中的数据是2。
  更新缓存的方案,有概率比较大的概率导致数据不一致的情况发生。因此,比较多人喜欢用删除缓存来代替更新缓存。(毕竟删除肯定不会带来数据不一致的问题,因为删了就没有了嘛)
  虽然如此,我个人觉得这个数据不一致的本质上是一种写冲突,因此实际上还是有不少方案来解决这个数据不一致的问题,我想了一下,大致有以下解决方案:
- last writer win
- lamport时间戳
- 版本向量
- 仿照读写穿透跟rocketMQ,来保证请求的顺序
至于为什么会选择删除缓存这种方案,我想这可能是最简单有效的吧。解决写倾斜,在这个场景中似乎没有带来性能的提升
Q:先操作数据库,还是先操作缓存
  在Cache-Aside-Pattern中,是先操作数据库。但是在读写穿透的方案中,选择了先操作缓存,再同步修改db。下面,我们讨论一下这两种选择,会有什么样的问题。
(1)先操作数据库,再操作缓存
  这种操作其实并没有特别大的问题,只是在某些情况下会发生一些小小的数据不一致问题。
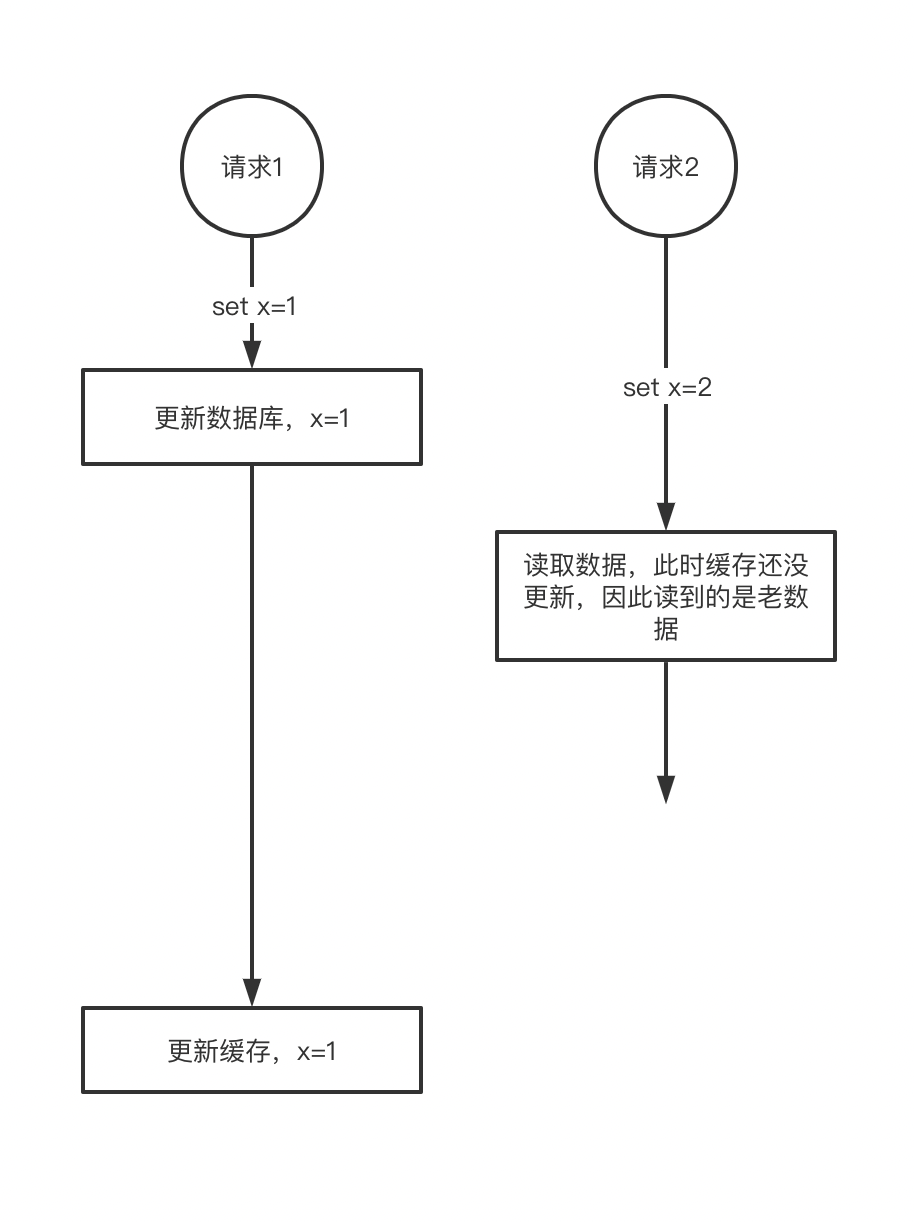
  两个请求,请求1进行数据库的更新,如果缓存还没更新的情况下。请求2,发出了一个读请求,并且快速返回数据给调用者,那么就返回的是一个旧数据。
  其实这个问题并没有什么大不了的,因为网络问题,导致数据更新不及时而已,数据总是会收敛到一致的,甚至连client也不知道自己拿到的数据是旧数据。
  但是,如果请求1和请求2是同一个client发出的,那么client就会十分困惑了。
(2)先操作缓存,再操作数据库
  这种方式我感觉,会带来比较严重的数据不一致问。我们还是假设有两个请求,如下图所示:
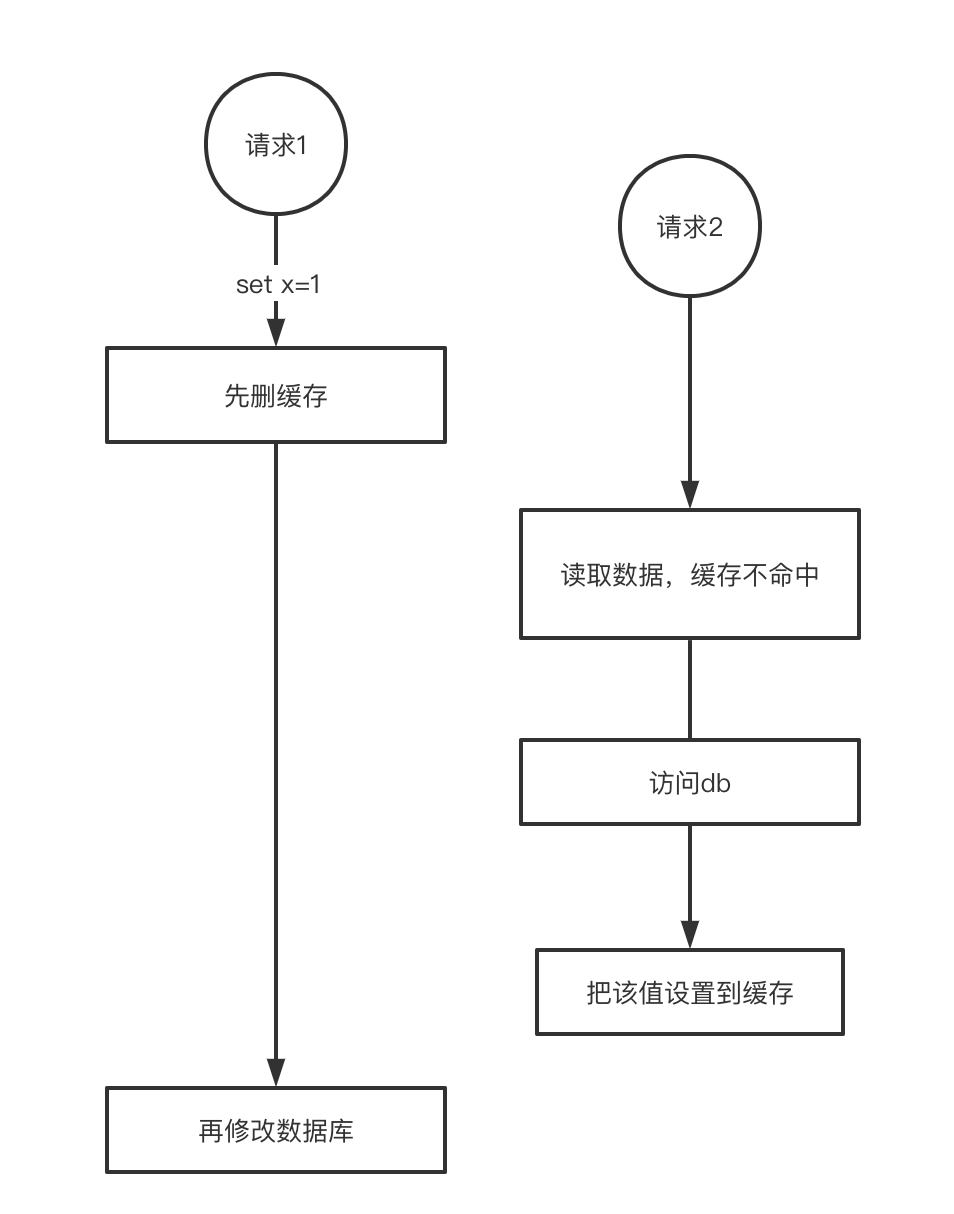
  一个写请求进行对记录进行更新,它删除缓存之后,马上来了一个读请求,此时cache中并没有数据,因此这个读请求需要到db里面请求数据。从db中拿到数据之后,需要把数据设置到缓存里面。那么此时,就出现了缓存是旧值,数据库是新的值。这种数据不一致还是比较严重的。我想这种操作,需要在缓存设置存在时间。
我认为,如果采用删除缓存方案的话,应该要把操作缓存的步骤放到最后。不然就会出现上面的情况了。
那么为什么读写穿透没有这种问题,其实我觉得有以下原因:
- 因为这时更新缓存,不是删除缓存。这样如果有读请求过来的话,它会访问到缓存,并直接返回数据。并不会走到db
- 因为请求都是统一由
cache provider进行管理。因此,完全有能力去管理这个请求的先后顺序。
(3)双删
  这种,其实是为了针对情况(1)的不足而设计的。在该情况下,因为更改了数据库之后,还没更新数据库。这时读请求过来了,但是这个请求就会被,存储了旧数据给打发走了。
  因此,双删这种策略,就是在修改db之前,先进行一个缓存删除的操作。如果是用Cache - Aside - Pattern模式,先进行db的操作然后再对缓存中的数据进行删除。那么此时会出现一个小小的数据不一致的问题,比如说更新数据库成功后,缓存还没来得及删除,此时一个读操作就会被旧的缓存打回去,会读到旧的值,与db不太一致。
  因此,多了双删这种策略。但是,其实在非常极端的情况下依旧会出现数据不一致的情况发生。
思考
  上面说的三种缓存使用模式,实际上都会有或多或少的缓存 - 数据库 不一致的问题。归根结底还是那个问题,因为操作数据库和操作缓存合起来不是一个原子性的操作,因此总会有一个时间点让数据不是自洽的,会发生不一致问题。
  可能是因为分布式系统,很难实现类似MVCC的机制因此数据很难在一次“事务中”是自洽的。又或者说,实现分布式事务的性能开销实在是太大了。
  总之呢,这三种方案还是要结合场景来使用的。不过我个人用的比较多的还是Cache - Aside - Pattern模式。其实,在我们大多数的使用场景中,缓存都是读多写少更新少。因此,大多是情况下放入缓存的数据都是更新频率很低的数据,导致极端的数据不一致的情况发生。还有,我们应该要防止”数据库是新值,缓存是旧值“的情况发生,因为这样该记录的缓存很长时间内都不会发生修改,会一直返回给调用方错误的值。因此,我觉得大多数读为主的场景,可以考虑该方案。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!