消息队列学习笔记 - 1
消息队列可以解决哪些问题?
结合我们日常的开发工作,来聊聊怎么使用消息队列。因为我实习的时候是做电商业务的,所以接下来的大部分例子,我都是以电商业务来举例。
异步处理
在电商的一个下单步骤中,大致可以分为以下步骤:
- 前端收到请求
- 网关进行转发
- 风控
- 库存锁定(扣库存)
- 对应的购物车扣减,更新统计数据……
如果这个步骤没有优化,并且是同步进行处理的。那么这个流程的调用链就会很长,客户端发起一个下单请求,会等待很久才能返回一个结果,这造成的用户体验是很差的。
但是,上述步骤中,并不是所有操作的实时性要求都很高。经过分析,我们可以发现,只要库存锁定了,我们就可以认为,这笔订单已经生成了。其他的一些譬如统计的操作,可以让后台相对来说不那么着急执行。这实际上,是一种异步提高性能的操作,可以交给消息队列来做。
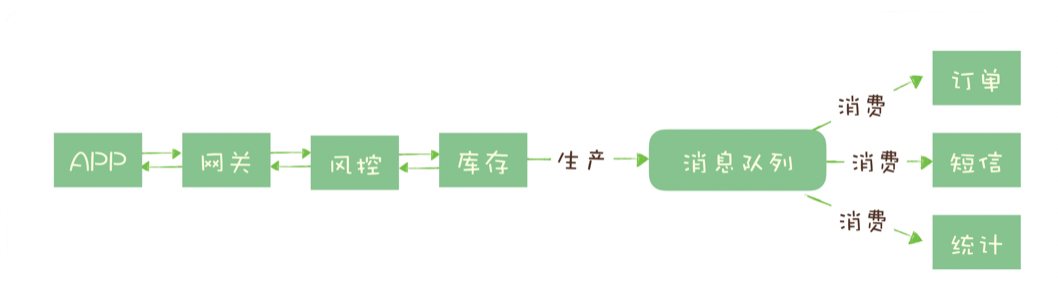
你看,这样一来,从用户的角度来看,服务的调用链就明显短了很多。可以看到,消息队列可以用作异步处理,这样做的好处有很多:
- 缩短调用链,更快的返回结果
- 如果下单并发量大的情况下,可以用更多的资源去处理下单请求。等到峰值过去后,再去处理后续步骤
- 提高了系统的性能
流量控制
上面说到了消息队列能够缩短调用链,异步处理我们的请求。甚至在下单请求比较多的时候,还能有比较好的效果。但是有一个值得注意的场景,如果前端收到大量的请求,直接全部涌到了调用链的入口,请求量太大超过了承受上限,那会发生什么问题呢?
- 请求太多,直接把服务打爆了,宕机下线
- 请求达到网关上线后,后面来的请求网关无法接收,导致请求丢失。
上面这个,其实是电商中经常会出现的场景,因此我们需要我们的下单服务有自我保护的能力,也就是我们的服务,应该是要按照能力去处理请求,避免出现流量过大打爆服务的情况。因此,我们可以在流量的入口使用消息队列,达到隔离网关和后续服务的作用,起到了限流以及保护的作用。
流量控制其实有两种方式,第一种就是让服务根据自身的能力往消息队列里面拿数据去消费,第二种就是通过令牌桶的形式。以上就是一般的流量控制策略,可以根据具体的场景来进行选择
服务解耦
什么是服务之间的耦合呢?我个人的理解是,服务之间依赖关系很强。举个例子,当一个新的订单创建时,一般会有这些操作发生:
- 支付系统,发起支付流程
- 物流系统更新
- 商家系统通知到商家
- 然后风控检测是否合法
- …
这些下游的服务都是依赖订单给出的数据,而且下游的服务一般也只是需要订单数据的其中一部分。随着业务的扩大,可能会新增服务或者原来的服务的接口需要改动。
但是每一次变更,必然需要订单系统进行修改(如果其他服务的调用,直接写在订单系统的代码里面的话),这样会十分麻烦。
针对这种情况,就可以通过消息队列来进行解耦。我们可以在消息队列上面发布一个TOPIC,订单服务往队列里面塞订单数据,然后下游服务就订阅该TOPIC。这样一来服务之间的耦合就解除了,订单服务就不用理会下游如何变化,是不是很方便
主流消息队列组件的优缺点
我在鹅厂实习的时候,leader给我开小灶的时候经常说到一句话,不要抛开场景谈技术选型。必须很了解某个组件/方案的特点,才能确定项目中为什么使用它。
so,接下来总结一下,目前市面上常见的主流消息队列
RabbitMQ
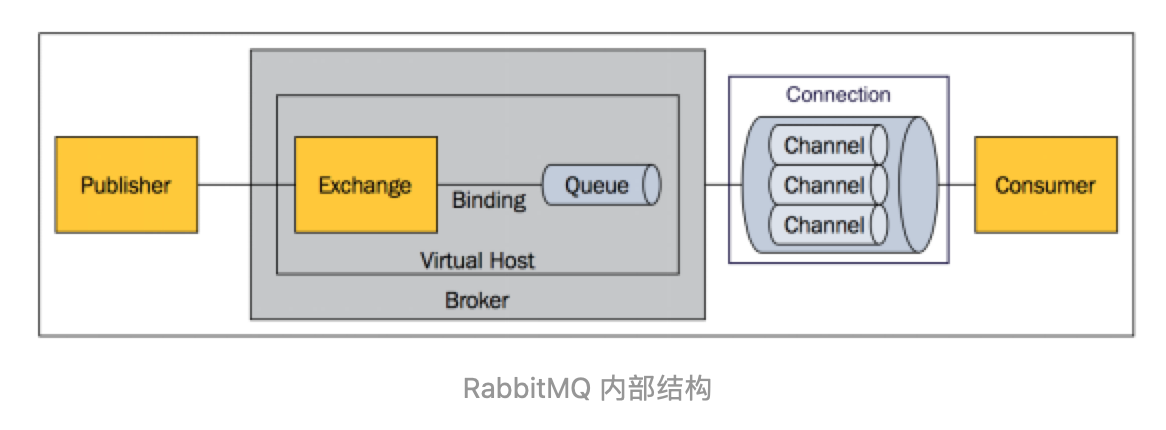
特点
RabbitMQ跟它的名字一样:跟兔子一样快。说明它是一个相当轻量级的消息队列,开箱即用,易于部署。
RabbitMQ还有一个比较灵活的特点,它和其他厂商的消息队列相比,多了一个Exchange。这个模块可以理解为一个交换机,它内置的路由规则十分灵活,甚至你可以配置属于自己的路有规则
客户端语言丰富,RabbitMQ支持的编程语言十分多,如果你是用一个比较少众的语言进行开发,我相信RabbitMQ会比较适合你。
缺点
RabbitMQ对消息堆积的问题不友好,没有什么好的处理方案。因为设计者认为,大量的消息堆积是一种不健康的行为,要去避免。因此当出现大量消息堆积的时候,性能会比较差。(虽然原本的性能也见不得有多好)
相对其他主流的消息队列来说,性能实在是不够看,每秒钟的处理能力在十万这个数量级。虽然说能够handle大多数的场景,但是如果你的项目对性能要求非常高,那么不建议你使用RabbitMQ。
编写RabbitMQ的语言十分小众,如果到时候遇到问题要修改源码,难度有点大
RocketMQ
阿里巴巴开源的消息队列,历经多次双十一的考验,因此它的性能和稳定性相当值得信赖。
在总结RockerMQ的特点的时候,似乎很难找到让人印象深刻的特点。几乎很多事情都做的很好。值得一提的是,经过几次双十一的优化,RocketMQ对业务的时延性做了不少优化,如果业务场景很在意时延,推荐使用RockerMQ。
Kafka
Kafka,是Apache基金会下的一个消息队列的项目。在它的初衷,它是用来处理海量日志的。
特点
- Kafka与周边生态兼容性十分好,尤其是跟大数据相关的组件,都支持Kafka
- Kafka的性能十分好,能够轻松达到几十万这个数量级,在配置比较好的情况下,达到百万级也挺容易的。
- Kafaka采用批处理和异步发送的思想
缺点
- 对在线业务可能不够友好,如果时延要求低的话尽量不使用Kafka。 (因为采用了异步批处理的方式,收到消息并不会马上发送,而是会攒起来,等等再发。)
三种消息队列小结
参考阿里巴巴官网给出的数据
| 功能 | RocketMQ | RocketMQ 开源 | Kafka | Kafka 开源 | RabbitMQ |
|---|---|---|---|---|---|
| 可靠性 | - 同步刷盘 - 同步双写 - 超3份数据副本 |
- 同步刷盘 - 异步刷盘 |
- 同步刷盘 - 同步双写 - 超3份数据副本 |
异步刷盘 丢数据概率极高 |
同步刷盘 |
| 低延时 | - 支持低延时 - 效率极高 |
不支持 | 支持低延时 | 不支持 | 不支持 |
| 定时消息 | 支持 可精确到秒级 |
支持 只支持18个固定 Level |
不支持 | 不支持 | 支持 |
| 事务消息 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 顺序消息 | - 支持 - 跟它的结构有关 |
- 支持 - 跟它的结构有关 |
不支持 | 支持 | 不支持 |
| 全链路消息轨迹 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 消息堆积能力 | - 百亿级 - 不影响性能 |
- 百亿级 - 影响性能 |
- 百亿级 - 不影响性能 |
不支持 | 不支持 |
| 消息重试 | 支持 | 支持 | 不支持 | 不支持 | 支持 |
| 消息堆积查询 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 性能 - 常规 | 百万级 | 十万级 | 百万级 | 百万级 | 万级 |
| 性能 - 十万TOPIC | 百万级 | 十万级 | 百万级 | 差 | 差 |
| 性能 - 海量消息堆积场景 | 百万级 | 十万级 | 百万级 | 差 | 差 |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!