redis单线程为什么这么快?
今天我们来讨论一个问题,“为什么单线程模型的redis,会这么快?”。在我们学习redis的时候,给我们的第一感觉就是,它很快。然而,慢慢深入的学习中,我们发现redis实际上是一个单线程模型。然而单线程模型跟快,往往是矛盾的。那么,今天我们就来探讨一下这个问题,redis的单线程模型是什么,而且为什么它很快?
要弄明白这个问题,我们要了解redis单线程的设计以及多路复用的机制。So,let’s go!
Redis单线程模型
首先,我们需要搞清楚redis的单线程模型它到底指的是什么?实际上,redis的单线程模型是指Redis的网络IO和键值对读写是由一个现场完成的,该线程所做的东西,就是保证redis能够对外提供存储和读取服务。
然而,redis的其他功能就不是由上面说的线程去做的。举个例子,redis的bgsave功能就是fork一个子进程出来,后台进行数据的备份。类似地还有很多,比如异步删除,集群的数据同步都是fork出不同的进程来进行处理。
为什么redis不采用多线程?
首先要明确一点,redis是一个IO密集型的程序。
刚开始学习多线程的时候,我们听到一个说法,多线程程序能够很大的提高系统的“吞吐量”。其实不然,我们还是要结合场景去看待这个事情,要分清应用是属于CPU密集型还是IO密集型。
那为什么不采用多线程呢?我个人觉得有以下几点的原因:
- 原因一:多线程之间切换开销大,随着线程数目的增加,系统的吞吐率会遇到瓶颈。
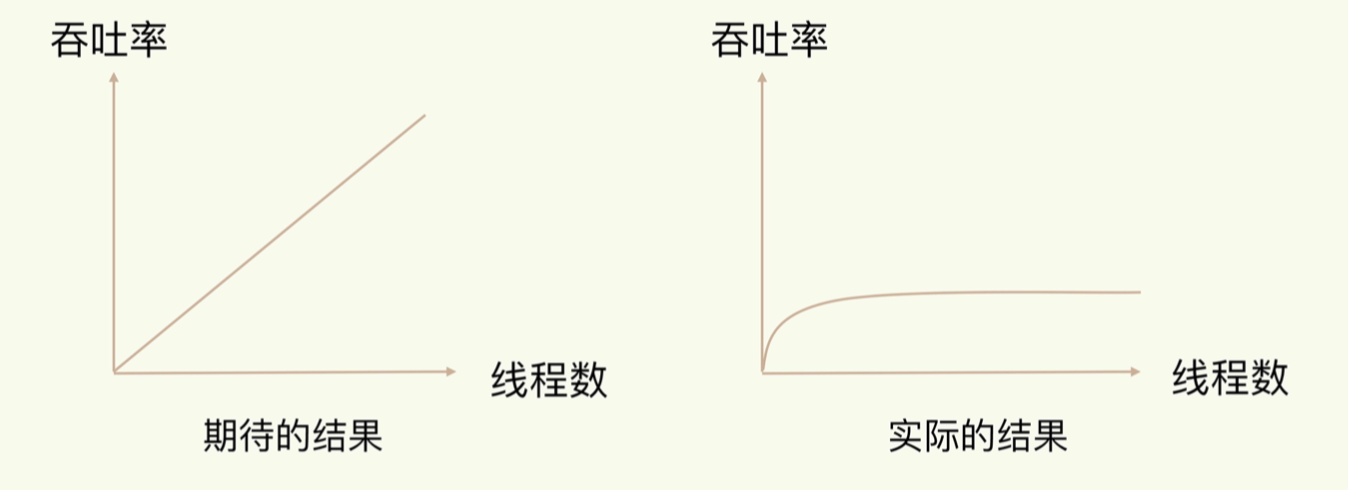
redis的性能瓶颈在于网络IO,因此即使是提高线程的数目,但是大部分还是会处于IO状态,并没有能够很好的提高系统的性能。因此,redis设计者对于该部分(处理客户端的连接)设计成了单线程。
有人会问了,如果用一个线程去处理所有客户端的连接,这个效率会不会很慢?其实不会,这得益于Linux的IO多路复用机制
- 原因二:多线程对于共享资源的处理,有额外的开销
1 | |
redis单线程为什么快?
通常单线程的处理能力都比较差,但是redis却能够轻松达到每秒十万级的处理能力。这我们不得不惊叹redis巧妙的设计了。
- redis大部分操作都在内存上完成,并且采用的数据结构十分简单且高效,因此即使是在单线程的情况下,也有很强的处理能力
- 另一方面,上面说了redis的瓶颈其实在于网络IO,设计者采用了IO多路复用的机制,让其能够并发处理客户端请求。
Redis与IO多路复用
接下来,我们来看看网络操作的IO模型(Socket编程)以及有哪些地方会引起阻塞。因为redis用单线程进行处理客户端请求,如果这个线程被阻塞了,必然会很影响redis的性能,那么我们看看redis是怎么设计的。
处理一个Get请求
以redis处理一个Get请求为例,它的步骤大致是这样的:
Redis服务器,创建一个主动套接字(Socket),并绑定到某个端口上(bind)
服务器,监听(listen)该端口,如果客户端有请求过来,则建立一个半监听套接字
三次握手完成后,建立连接(accept),在Linux中一个TCP连接是用文件描述符Fd来表示
服务器监听该TCP连接,看是否有数据,如果有则取出来并解析。
服务器解析完请求后(假设是Get请求),则执行get命令,得到结果并通过socket返回给客户端
以上这些步骤除了在本地处理get请求外,都是属于网络IO的范畴。既然是单线程,那么最普通的做法就是用一个线程去执行上面这些步骤。
1 | |
一般来说,引起阻塞的步骤其实主要有两个。步骤3(accept),如果redis监听客户端请求,得到一个监听关键字,但是客户端和服务器没有完成第三次握手,导致连接无法建立,但是我们看代码,这必然会引起其他客户端也无法跟服务器建立连接。
步骤四,服务器监听该socket,如果一直得不到信息,同样也会影响别的客户端。
这就回导致,redis效率很低。不过幸好,socket编程支持异步模式。
非阻塞的Socket编程
其实主要有两点:
- 针对监听套接字,监听关键字调用accept( )后,可以去处理别的事情了,即使没有收到第三次握手的请求
- 针对连接套接字,调用接受recv( )后,就可以去处理别的事情了,即使该Socket没有收到数据
这种机制,就保证了Redis线程,并不会阻塞在IO的某一个步骤。虽然如此,这也仅仅保障了Redis处理客户端连接的线程不会被阻塞,但不能让他高效处理大量的客户端请求。
为了能处高效处理大量的客户端请求,就需要用到Linux的多路复用
redis中的多路复用
如果不知道多路复用是什么,可以点击—-> IO多路复用视频
该机制下,可以同时在内核监听多个套接字。一旦有请求到达并且完成,就会把它交给redis线程去处理。这就实现了一个Redis线程,同时处理多个客户端请求的效果。
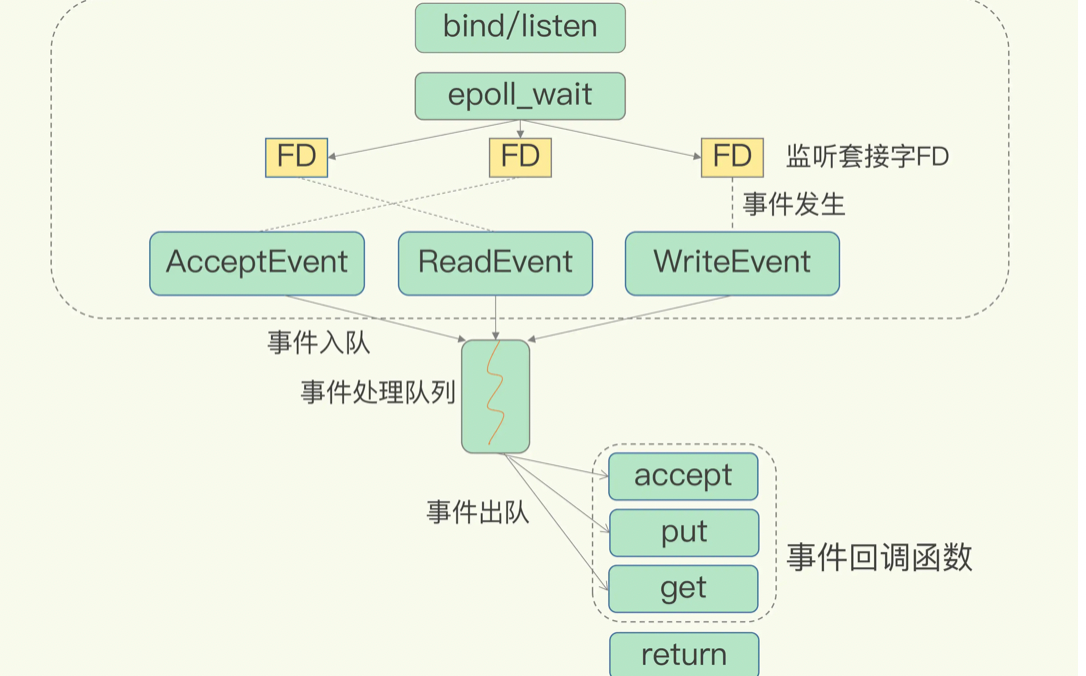
当内核中监听到请求到达时,就会为不同的套接字注册不同的回调函数。并把它塞到事件队列里面。
这些事件会被放进一个事件队列,Redis 单线程对该事件队列不断进行处理。这样一来,Redis 无需一直轮询是否有请求实际发生,这就可以避免造成 CPU 资源浪费。
同时,Redis 在对事件队列中的事件进行处理时,会调用相应的处理函数,这就实现了基于事件的回调(针对不同的fd,注册不同的回调函数)。因为 Redis 一直在对事件队列进行处理,所以能及时响应客户端请求,提升 Redis 的响应性能。
这就是Redis单线程的设计以及它的巧妙之处!
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!