浅谈数据库的锁(二)
前言
今天这篇文章,讲的主要是下面两个内容:(1)gap lock 和 next - key lock (2)锁,到底是锁的是什么东西?
并且想要解决几个令人困惑的问题
在主键,唯一键,普通索引,以及非索引字段加锁,究竟锁住来了什么东西?
不同的查询条件,锁住什么东西?
条件中的等值不存在,锁住什么?
间隙锁 gap lock
为什么有间隙锁,其实这个是幻读带来的。产生幻读的原因在之前的文章说过了,(1)通过条件查询 (2)应用层逻辑判断 (3)根据条件进行DML操作。
如果一个事务符合这三个特点,就很可能有幻读的问题。因为(3)的DML操作的前提条件依赖(1)的一致性试图。但是如果有别的事务,破坏了这个条件,并且在当前事务执行(3)之前先提交了。那么(3)它依赖的条件,虽然在当前条件的视图中看起来是自洽的,但是实际上前提条件已经被破坏。这就是幻读产生的原因。
因此,需要一个锁,把(1)中查询出来的全部锁住。不仅如此,甚至对”不存在的,并且在条件范围内的也要锁住“,参考创建用户名的例子
so,gap lock应运而生。
接下的讨论基本都是在此表的基础上展开
1 | |
gap lock 如何解决幻读
产生幻读的原因是,行锁只能锁住行,但是新插入记录这个动作,要更新的是记录之间的“间隙”。
因此,为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁 (Gap Lock)。

然后,如何解决幻读呢?如上图,其实根据(1)条件进行查询之后,会对那些间隙进行加锁。只要间隙上面有了锁,那么其他事务无法对其进行DML操作。
and,我们还要讨论一下,gap lock阻塞的是什么东西。其实很简单,就两个特点:
- 跟gap lock发生冲突的是 往间隙里面进行插入操作
- gap lock 跟 gap lock之间是不冲突的。
- (0,10)和(2,9)或者( 1,11)都是不冲突的
- 间隙之间有无交集都是不冲突的
next - key lock 间隙锁升级
间隙锁和行锁合称 next-key lock,每个 next-key lock 是前开后闭区间。 如果上面,那个表用了select * from t for update。那么就会出现七个next-key lock。
1 | |
锁到底锁的是什么?
1.以下讨论的都是写锁(排他锁),share mode没必要讨论
2.都是基于上面创建的表,进行讨论
要讨论锁到底锁的是什么,大致要分以下几种情况来讨论:
- 主键(唯一索引),条件命中
- 主键(唯一索引),条件不命中 / 条件模糊
- 普通索引,条件命中
- 普通字段,条件命中
主键,条件命中
1 | |
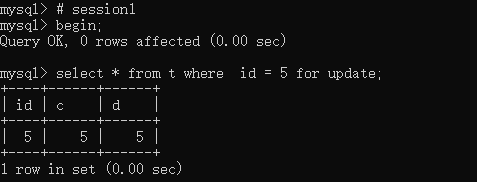
ok,我们来看一下,这种情况下的锁是怎么样的。在主键存在的情况下,加锁的情况是这样的:
- 只有命中的那条数据,加上了row lock
- 主键命中的情况不存在gap lock

1 | |
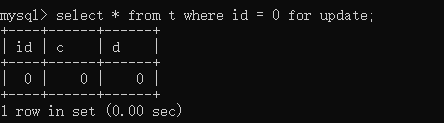
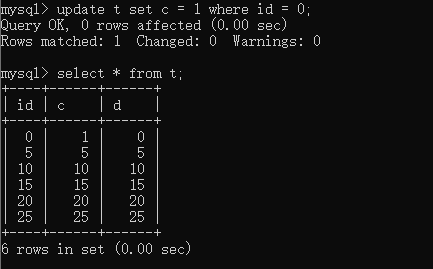
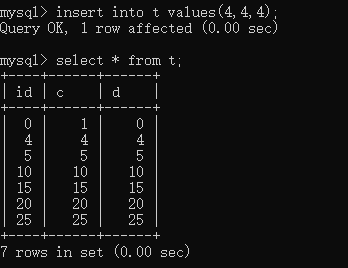
主键,条件不命中
1 | |
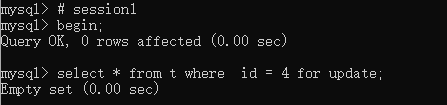
在条件不命中的情况下,锁是这样的:
- 行与行之间加上gap lock
- 所有行记录都不加row lock
1 | |
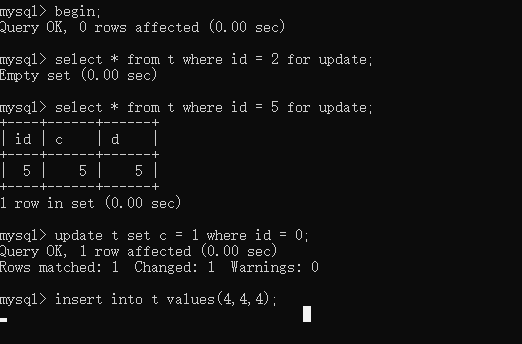
索引,条件命中
1 | |
普通索引,条件命中的情况下,锁的情况是这样的:
- 命中的,是行锁,行锁加在主键上
- 其余是gap lock,gap lock加在其他索引树上(在该表中,加载索引c的b树上
1 | |
- 对于查索引命中的行,加的是行锁。


id = 25,不是查出来的数据,可以更新d字段。
个人认为,行锁是加在主键上的,这样可以避免 通过别的索引,修改已经查出来的行
- 在对应的索引树上,加gap lock。不影响其他索引树

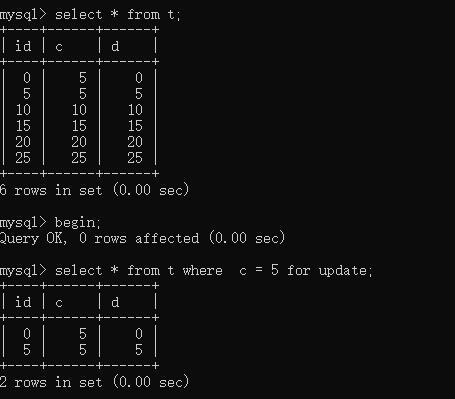
(1)对于update t set d = 5 where id = 10
因为,行锁只加在查询出的(id = 0 和 id = 5)两条数据里。gap lock是加载字段c的索引上。当这条记录更新完成,并不会更新字段c的索引树。因此能够运行
(2)对于update t set c = 4 where id = 0
显然是因为行锁,这语句被阻塞了。
(3)对于update t set c = 5 where id = 10
id = 10不是查出来的数据,但是对行记录更新完成后,因为操作的是索引字段c,因此需要对字段c的索引树进行修改。修改索引树的过程遇到gap lock被阻塞了
索引,条件不命中
1 | |
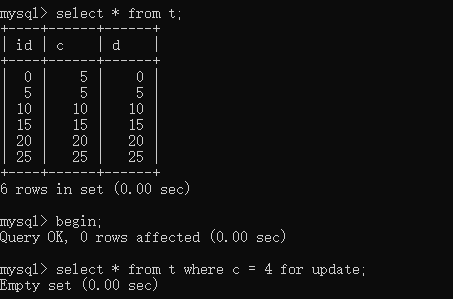
该情况下,加锁的情况:
- 只对整个字段c索引树加gap lock
- 不存在 row lock
原因不解释了,跟上面的差不多
1 | |
普通字段
表中的数据
1 | |
对于非索引字段,整个表都是加的表锁
1 | |
行锁到底锁的是主键还是普通索引?
为了验证我们的想法,我们需要在原来的表中,新建一个索引。这个索引就建在字段C上面吧
1 | |
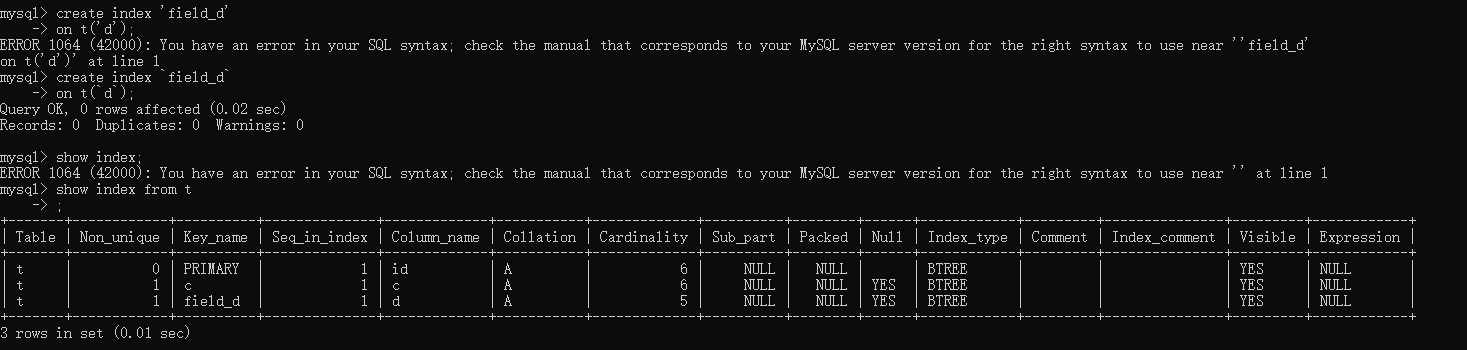
ok,现在原来的表中有两个普通索引c和d了。
1 | |
分析:
- 已知,索引树c和索引树d是独立的。
- 如果行锁加载索引树上,那么索引树c上对id=5的加行锁,不影响在索引树d对id=5加行锁
- 如果加载主键上,必然被阻塞。
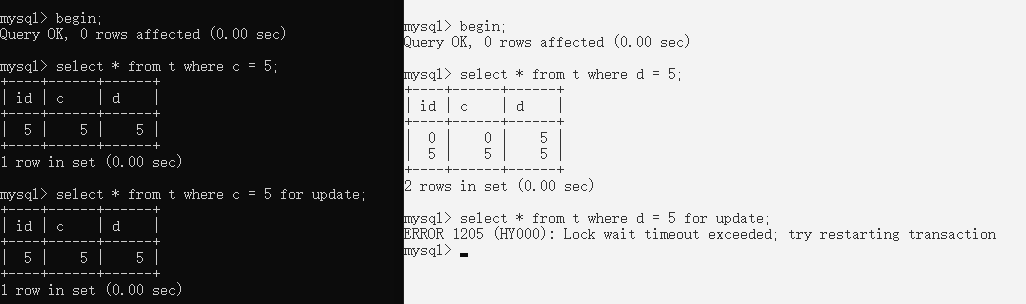
ok,索引树d的操作被阻塞了,显然,行锁是加在主键上的。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!