浅谈用户态和内核态以及系统调用
前言
  为了保证操作系统的强隔离性,设计者实现了“supervisor mode” 和 “虚拟内存”,来保证进程之间互相隔离。
  我们可以认为user/kernel mode是分隔用户空间和内核空间的边界,用户空间运行的程序运行在user mode,内核空间的程序运行在kernel mode。操作系统位于内核空间。
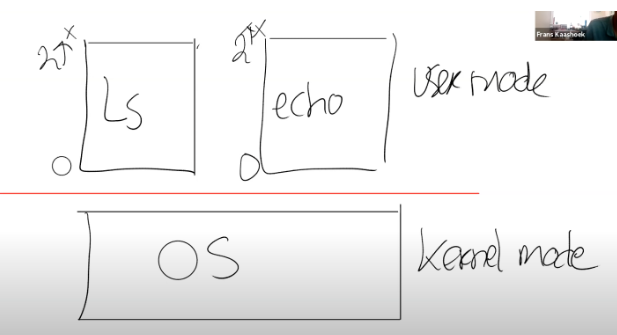
  一般来说,用户态的应用程序运行在用户态空间里面。但是,一些比较重要的函数,操作会发生在内核空间。因此,内核空间拥有更多的权限,能够访问更多的底层数据结构,以及指令。
  那么,我们来看看如何从 用户态陷入到内核态 (trap)
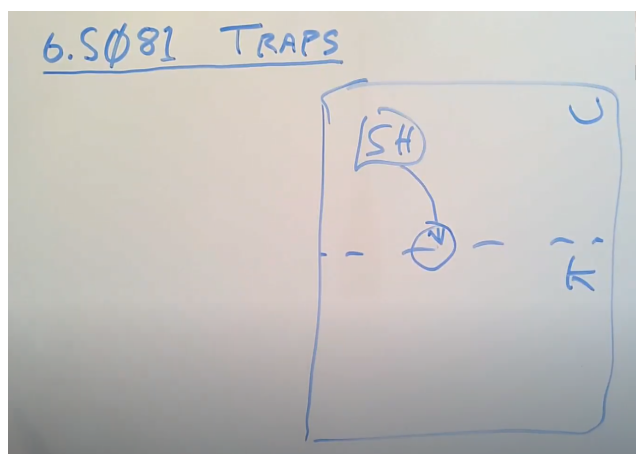
Trap机制
今天我想导论一下,程序是如何完成用户空间到内核空间的切换。每当发生下面的以下情况发生时:
- 程序需要系统调用
- 程序出现缺页,页表错误
- 设备发出了中断
都会发生mode的切换。这种切换机制叫做trap。
  下面,举一个Shell进程,执行write()系统调用的例子。看看程序是如何完成用户态到内核态的切换。
  我们有一点需要知道的是,当用户态程序进入到系统态的时候,这个过程中硬件的状态非常重要,需要我们保存下来。因为,trap过程中需要设置cpu状态,这样才能让内核程序运行(这里我理解是保存CPU的现场或者说上下文信息)。
  因此,为了恢复用户态程序,需要把切换时的CPU现场保存下来。需要注意的寄存器有下面这些
- 32位用户寄存器
- stack pointer (指向程序的栈)
- pc
- mode位 (标志系统处于哪个状态,user mode or supervisor mode)
- STAP — Supervisor Address Translation and Protection — (包含指向page table的地址)
- STVEC — (trap指令的起始地址)
- SEPC — (执行trap过程中,保存PC)
- SSRACTCH — (保存trapfram的地址)
- trapfram是用来保存CPU现场的一个重要数据结构
  可以肯定,trap机制刚执行的时候,cpu的状态是运行用户程序的状态。
  因此,刚运行trap指令的时候,我们需要做一些操作(保存当前CPU的上下文)。这样才能运行内核中的C程序。
保留32位寄存器,因为这是恢复的根本
PC,同上
把
supervi mode设置为内核态STAP页表寄存器此时指向用户程序的页表,需要执行内核程序的话理所当然需要内核程序的页表。
trapframe中有指向内核的页表的地址- 把内核页表的地址,与当前
STAP寄存器中,用户程序的页表地址交换
也就是说,此时
trapframe中有用户程序的页表,STAP中有内核程序的页表Stack pointer也要指向进程内核栈。因为C程序的运行需要一个栈空间
以上,就是trap机制大概执行了什么事情。接下来我们从代码的角度来进行分析。简单来说,就是在CPU里面的状态位,设置为能够运行内核程序的状态。并且保存用户程序的CPU上下文。
Trap代码执行流程
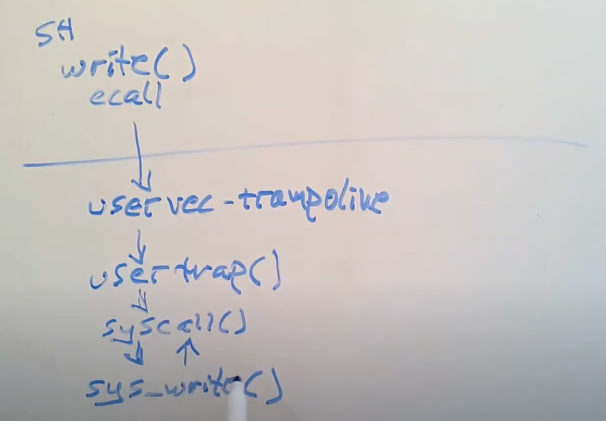
  Shell执行write( )系统调用。从Shell的角度来看,write( )是一个C函数调用。但是,从汇编的角度来看,write( )通过ecall num,来具体执行系统调用。
  ecall指令会切换到kernal mode中去。在这个过程中执行的是一个汇编语言写的函数uservec。这个函数是内核代码trampoline.s的一部分。

  之后,在这个汇编函数,代码跳转到了由C语言实现的函数usertrap中。该函数在trap.c中。

在usertrap( )中执行了一个syscall指令,然后该指令通过number。在一个表里面,找到该number对应的系统调用。

sys_write会将显式数据输出到console上面,当它完成了之后,它会返回给syscall函数。
上面就是我们如何从用户态陷入到内核态,执行系统调用的过程,但是现在需要考虑是如何从内核态返回给用户态
在syscall函数中,会调用一个函数叫做usertrapret,它也位于trap.c中,这个函数完成了部分方便在C代码中实现的返回到用户空间的工作。

除此之外,最终还有一些工作只能在汇编语言中完成。这部分工作通过汇编语言实现,并且存在于trampoline.s文件中的userret函数中。

最终,在汇编代码中调用机器指令,返回到了用户控件中。

ecall指令执行前的状态
  从那个sh执行write( )系统调用,我们看一看执行ecall前后的寄存器状态。
  这是write的代码,很简单

现在,我要让XV6开始运行。我期望的是XV6在Shell代码中正好在执行ecall之前就会停住。
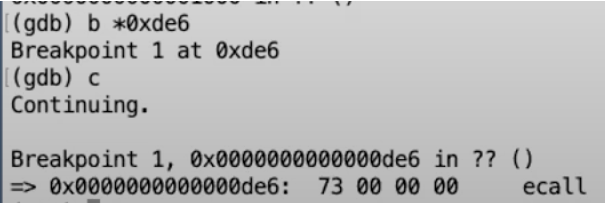
从gdb可以看出,我们下一条要执行的指令就是ecall。我们来检验一下我们真的在我们以为自己在的位置,让我们来打印程序计数器(Program Counter),正好我们期望在的位置0xde6。
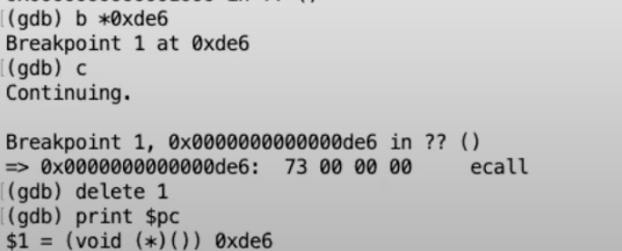
此时寄存器的状态

STAP页表寄存器状态以及内容

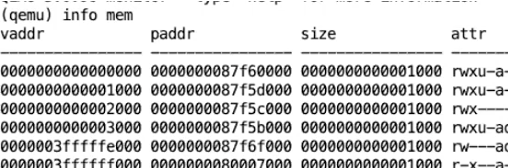
  最后两页明显不一样,因为这是trampoline page 和 trapframe page的地址空间,当我们进入到supervisor mode就能访问者两页。
ecall执行后的状态
当我们执行完ecall之后,查看一下PC的地址。很明显这是一个比较大的值,与ecall执行前的Oxde6不一样。

再查看一下page table。发现page table没有变化

我们发现,此时PC中的值跟trampoline page的值十分相似。那么我们查看一下trampoline page中的指令。
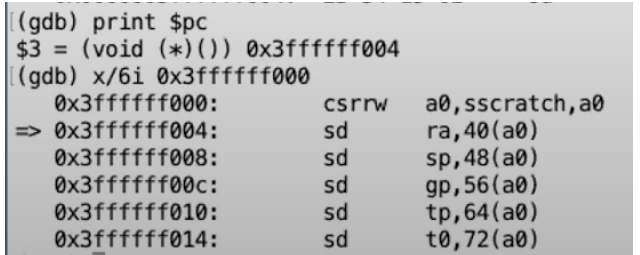
这些指令是内核在supervisor mode中将要执行的最开始的几条指令,也是在trap机制中最开始要执行的几条指令。
因为gdb有一些奇怪的行为,我们实际上已经执行了位于trampoline page最开始的一条指令(也就是csrrw指令)。
我们查看32位寄存器的值,发现并没有改变。所以寄存器还是用户数据。再观察一下发现。
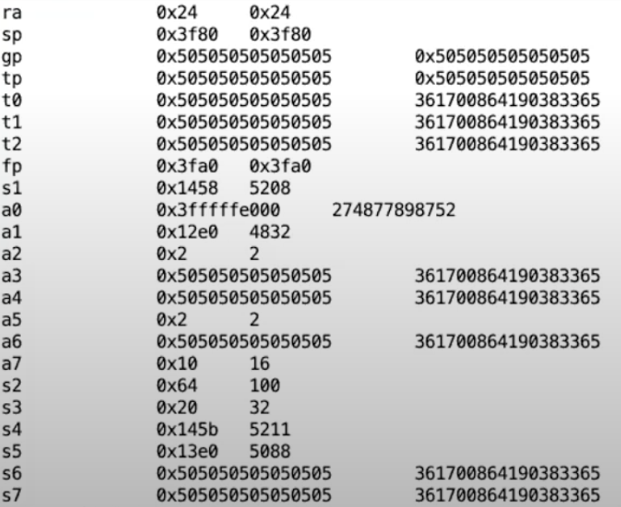
  当前执行的指令是把CPU的状态进行一个保存。也就是说trampoline page的指令是保存cpu寄存器的
  我们现在在这个地址0x3ffffff000,也就是上面page table输出的最后一个page,这是trampoline page。我们现在正在trampoline page中执行程序,这个page包含了内核的trap处理代码。ecall并不会切换page table,这是ecall指令的一个非常重要的特点。
1 | |
ecall做的事情
第一,把
user mode设置为supervisor mode第二,把当前的PC值放到SEPC寄存器中,以便系统调用结束后,能够恢复原来的程序位置
- 至于保存CPU现场,是
trampoline page里面的指令做的事情。所以,此时PC里面的指令是trampoline page
- 至于保存CPU现场,是
第三,ecall会跳转到
SPEVC寄存器指向的指令
打印当前PC,是trampolin page的地址,也是SPEVC的地址

打印SEPC寄存器,是用户态PC的值

所以执行完ecall,我们仅仅是改变了supervisor mode 和 pc的值
此时页表和栈的信息,仍旧是用户程序的。因此,我们接下来的工作:
- 保存32位现场(trampoline page代码)
- 切换
page table - 切换
进程栈空间
为什么ecall做的事情这么少
  实际上,我们也可以通过在硬件上进行处理,通过修改硬件让ecall帮我们执行完这些。但是,RISC-V秉持了这样一个观点:ecall只完成尽量少必须要完成的工作,其他的工作都交给软件完成。
  这里的原因是,RISC-V设计者想要为软件和操作系统的程序员提供最大的灵活性,这样他们就能按照他们想要的方式开发操作系统。
  让ecall指完成基本的功能,那些开销很大的操作,有可能是不用做的,那么就没必要放到ecall里面,让ecall指令更加的效率。
- 举个例子,因为这里的ecall是如此的简单,或许某些操作系统可以在不切换page table的前提下,执行部分系统调用。切换page table的代价比较高,如果ecall打包完成了这部分工作,那就不能对一些系统调用进行改进,使其不用在不必要的场景切换page table。
- 某些操作系统同时将user和kernel的虚拟地址映射到一个page table中,这样在user和kernel之间切换时根本就不用切换page table。对于这样的操作系统来说,如果ecall切换了page table那将会是一种浪费,并且也减慢了程序的运行。
- 或许在一些系统调用过程中,一些寄存器不用保存,而哪些寄存器需要保存,哪些不需要,取决于于软件,编程语言,和编译器。通过不保存所有的32个寄存器或许可以节省大量的程序运行时间,所以你不会想要ecall迫使你保存所有的寄存器。
- 最后,对于某些简单的系统调用或许根本就不需要任何stack,所以对于一些非常关注性能的操作系统,ecall不会自动为你完成stack切换是极好的。
所以,ecall尽量的简单可以提升软件设计的灵活性。
uservec函数
保存CPU现场
  刚才提到了trampoline page里面的代码是为了保存寄存器状态。但是现在有一个问题。
  在大多数的OS里面,是不能直接访问物理内存的,需要通过page table做一个映射。因此我们需要拿到kernal的page table。但是目前为止,我们并不知道它的page table地址。
并且更新page table的寄存器,我们需要先把用户程序的page table进行保存,这样我们才能再修改。
因此总结一下我们需要解决的两个问题:
1 | |
  这个做法其实十分简单,还记得user page table,最后的两页是什么内容吗?trampoline page 和 trapfram page的起始地址。
  我们看看trapfram page中究竟存储的是什么东西?
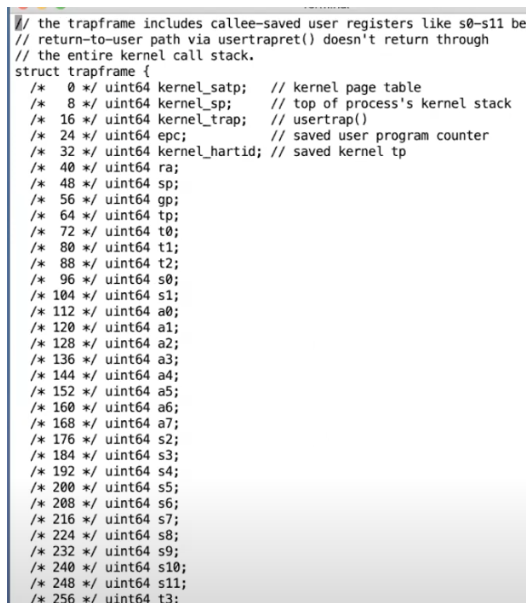
  很显然,trapfram的字段都是对应着CPU里面的寄存器。但是多了五个数据,这是内核事先存放好的数据
- 比如,第一个字段就存放着kernal page的地址
- 第二个字段是栈
- 第三个是usertrap代码的起始地址
- 第四个是SEPC寄存器
所以很显然了,我们需要的kernal page就在trapframe中就可以找到。
  另一半的答案在于我们之前提过的SSCRATCH寄存器。(可以理解为box)
  在回到用户态之前,内核会把trapframe page的地址保存在这个寄存器。更重要的是csrrw指令,能够交换两个寄存器的值。
  我们看一下trampoline.s的代码

第一件事情,就是交换a0和ssratch两个寄存器的内容,我们通过gdb查看一下。显然a0就是等于trapframe

打印一下ssractch,显然就是之前的a0
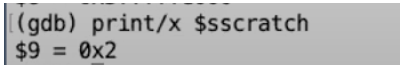
  所以我们现在将a0的值保存起来了,并且我们有了指向trapframe page的指针。现在我们正在朝着保存用户寄存器的道路上前进。通过计算位移,来保存寄存器的内容到trapframe。
1 | |
切换栈空间
  程序现在仍然在trampoline的最开始,也就是uservec函数的最开始,仅仅执行了CPU现场保存。我在寄存器拷贝的结束位置设置了一个断点,我们在gdb中让代码继续执行,现在我们停在了下面这条ld(load)指令。
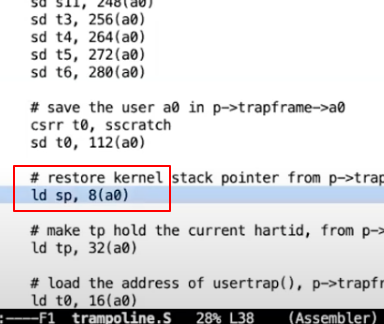
也就是,加载trapfram中的第八个字节到stack_pointer寄存器中。我们查看一些trapframe中第八个字节是什么东西?
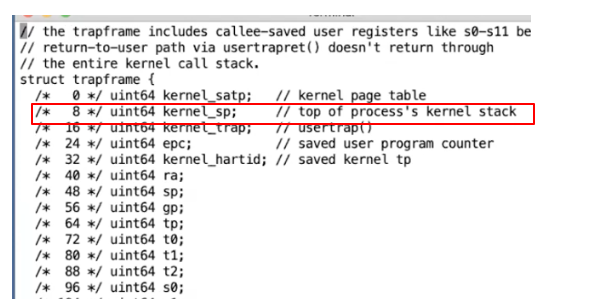
  显然很明显,该指令就是切换到内核栈上。这是这个进程的kernel stack。因为XV6在每个kernel stack下面放置一个guard page,所以kernel stack的地址都比较大。
1 | |
切换page寄存器
有一条指令是向t1寄存器写入数据。这里写入的是kernel page table的地址,我们可以打印t1寄存器的内容。

  这条指令执行完成之后,当前程序会从user page table切换到kernel page table。现在我们在QEMU中打印page table,可以看出与之前的page table完全不一样。

以上,就是从用户态陷入到内核态的所有流程。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!