why B+ tree?
数据库的索引,我想都并不陌生,简单来说,索引的出现就是为了帮助更快的进行查询。索引就像书的目录一样,帮助你快速定位想要的章节所在的地方。
索引能用的数据结构有很多,hash,有序数组,二叉树平衡树,红黑树,B树,B+树……但是为什么innodb引擎,最后选择B+树作为索引?下面我们来聊聊索引的各种优缺点
Hash索引
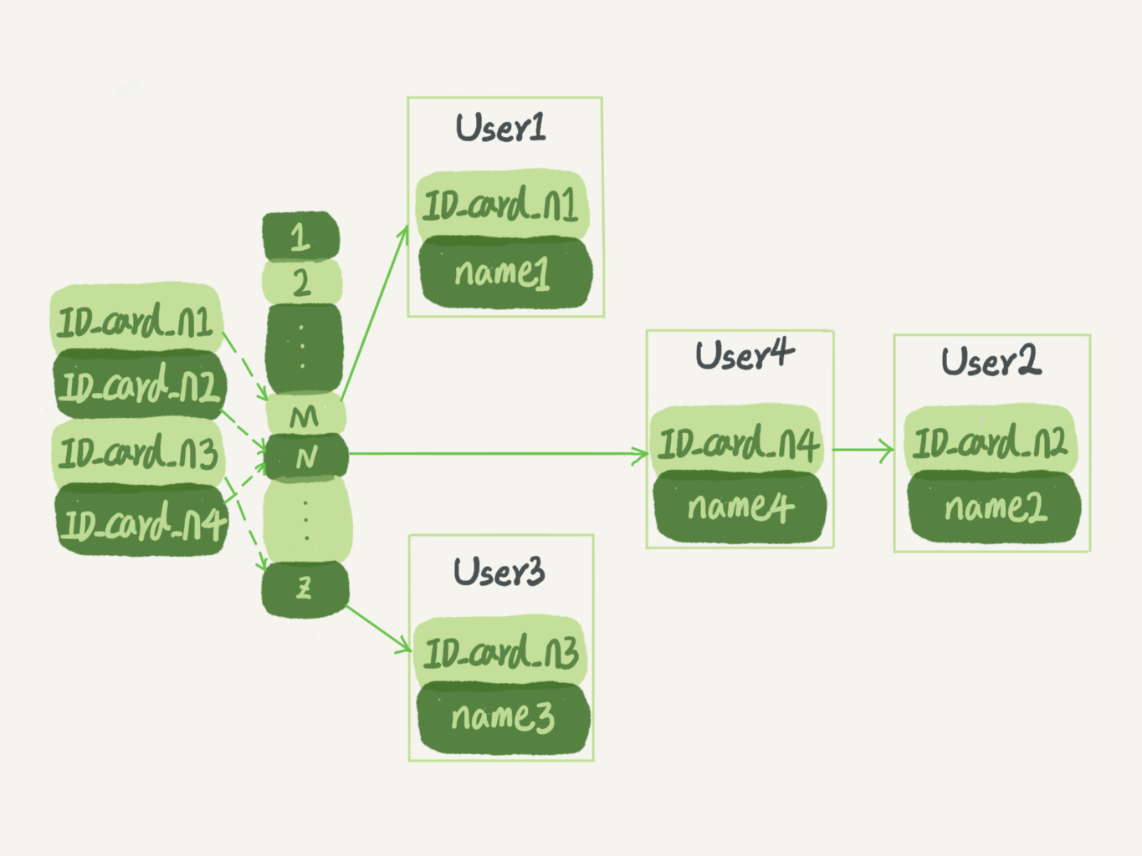
索引 - 记录所在的位置,实质上很像很像一种 K-V结构。那么哈希表是对这种结构的检索效率是很高的。
下面,我从使用的角度来简单分析一下这种数据结构。
哈希表是一种以 K - V 键值对来存储数据的数据结构。插入的时候根据key值,算出该键值对所在的数组位置。然后从该位置拉出一个链表,然后进行插入。
缺点一
这种数据结构做索引有个比较明显的缺点:hash冲突,对于hash表这种数据哈希冲突在所难免,这也是hash索引影响性能的一个原因。
不妨假设一个这样的场景,100w条记录的数据库因为hash冲突比较严重,需要进行扩容。一般来说,扩容有两种方案 (1)直接扩容 (2)渐进式rehash。
我的想法是,两种扩容方法对于这个量级的数据库来说都不太好。
- 方案一,同步阻塞的时间过长了
- 对于方案二,因为rehash是需要fork一个子进程来进行rehash,这必然在一定程度上影响CPU的性能。
缺点二
范围查询不友好,这点放在B树B+树说。对范围查询友好的索引,一般来说只有这两个。
Q:如果采用SSD,检索/IO很快,hash索引的范围查询时间会和B+树差不多嘛?
1 | |
缺点三
个人觉得,hash索引的并发度不会太好。以下,仅讨论 间隙锁(范围锁)。为什么这么说呢?其实从他的结构上我们就可以看出来
hash索引在数据的组织上,并没有逻辑上的有序,因此没办法向B+树那样直接加锁。并且对于空的记录,没办法锁
这锁加在哪里?加在节点上吗?那么第一步是要对范围内的记录进行查询,上面已经说了,哈希索引对范围查询不友好,因此不行。
锁加在链表(数组),这样加锁的话,显然不行,因为该链表上的数据不是所有的节点都符合加锁的条件的。
因此,考虑以上原因,hash索引的并发性真的不够强。
所以,哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。 对于redis来说哈希是一个很重要的数据结构。
有序数组索引
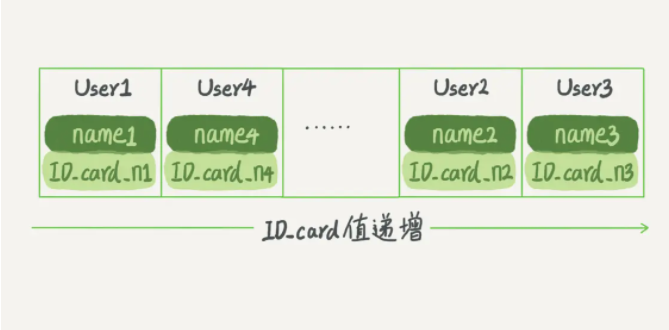
有序数组很简单,就是拿数组进行存储。但是这个存储是有条件的:插入的数据必须是严格自增的。如果你插入了 1,10。那么下一条的数据只能大于10,不能插入9。
为什么要这样?原因很简单,避免空间的浪费。
并且,这种索引的查询效率很好,因为可以用到二分查找。因为在存储的时候逻辑上是有序的,因此它范围查询也很好。
因此,只要它的场景符合,插入的数据都是严格自增的,那么就可以采用这种索引。
二叉树索引
这里就不说普通的二叉树了,因为普通的二叉树可能会出现树高不平衡的问题。下面所说的树都是平衡树。
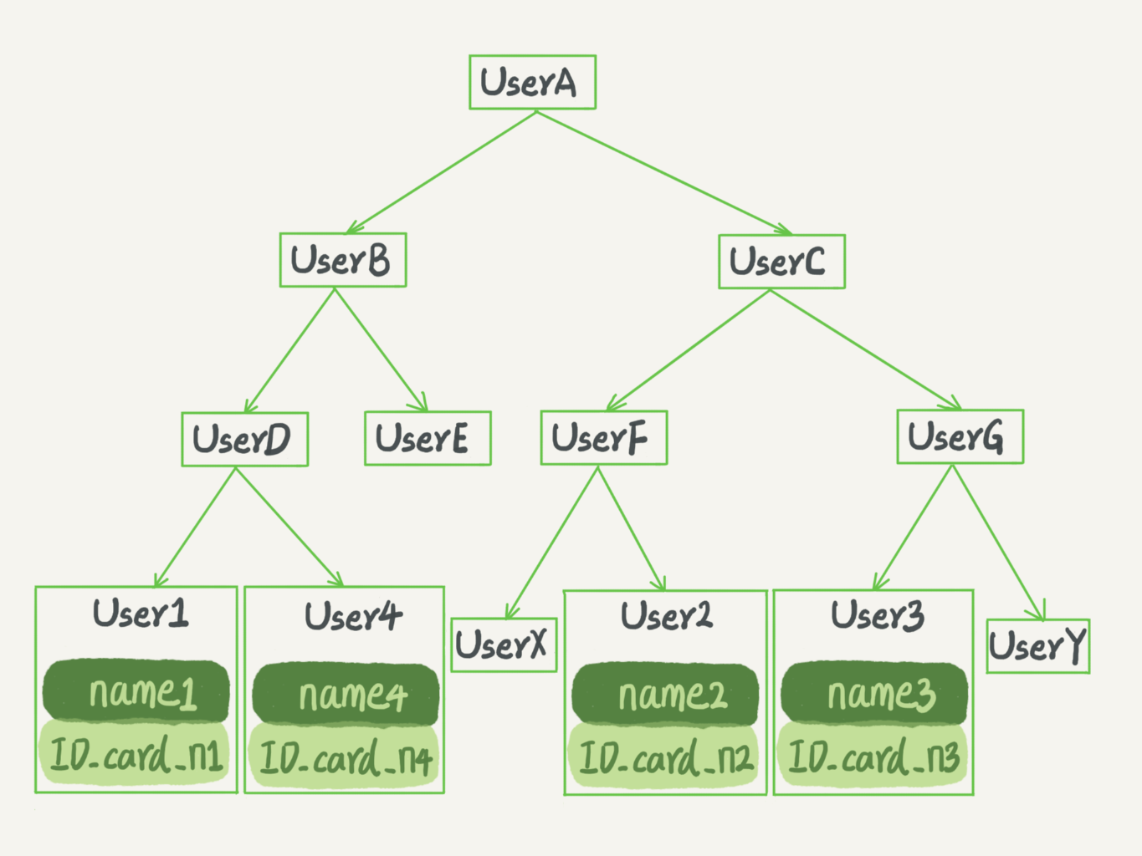
这种数据结构的特点,不管是对于查找还是插入都十分友好。并且不像有序数组索引那样,要求索引字段必须是严格自增的。
理论上,二叉树的效率是很高的,但是为什么实际上数据库的存储都不使用二叉树?这个问题的答案是因为,一般来说索引很大,不可能只存在于内存上,一定要写入磁盘里面。
我们可以假设一个场景,100万条记录的表,它的二叉树高大概在20左右。我们知道在磁盘中,以块来存储的。那么查询一条数据,最坏的情况就是20 x 10ms = 200 ms。这个查询速度难以让人接受。
为什么使用N叉树
为了让一个查询尽量地少读磁盘,就必须让查询的过程中尽量少访问数据块。为了减少磁盘的IO,不妨考虑以下N叉树。
为什么要用N叉树,我们看N叉树的节点,一个节点存储多条数据,而且每个节点内的数据在逻辑上都是有序的。而数据块,也是存储多个数据。那么,我们可以不可以把数据块抽象成N叉树的节点呢?答案是,这种做法完全可行。
1 | |
OK,所以我们不使用二叉树作为我们的索引,是因为磁盘适配性。总的来说,采用B+树来个人感觉只是它的普适性最强,在各种各样的场景中都还有不错的效率。
但是,如果针对特殊的场景的话,我们还是可以选择其他索引的。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!