浅谈数据复制
数据复制
数据复制的目的
- 使数据中心更加接近客户端的物理位置,降低访问延迟 (提高效率)
- 当部分组件发生故障时,会自动切换到别的组件**(高可用性)**
- 拓展至多台机器以同时提供吞吐率
数据复制的所有技术挑战都是复制那些热点数据,如何把热点数据复制到别的节点上面。
主从复制
工作原理
对于每一个记录的写入,所有副本都需要更新;否则,某些节点会出现数据不一致的情况。
主从复制的工作原理如下:
- 指定其中一个节点成为master,其他节点为slave
- 所有写请求,转发给到master。slave则处理读请求。
- 当master做好本地存储之后,把这些操作通过binlog,发送给slave。然后让slave执行。
同步复制 与 异步复制
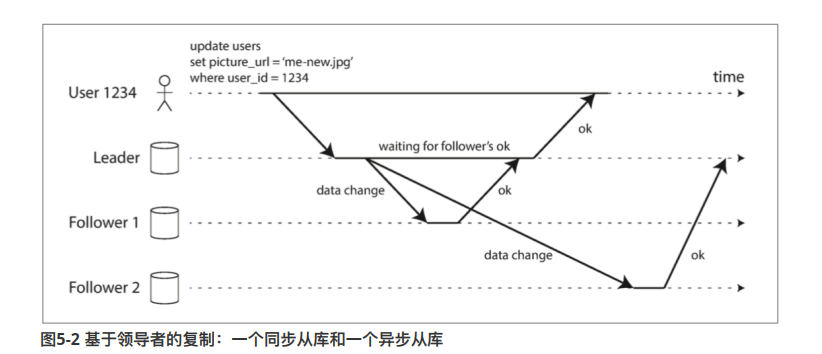
如图,master和从节点1之间的复制是同步的,即主节点需要等待从节点1的复制完成写入。
master和从节点2之间的复制时异步的,master发起一个复制后,不用阻塞等待,便直接提交了。等从节点2完成后,才真的向主节点发起一个确认。
同步复制的特点
- 主从节点之间数据的距离一定是很低的,因此如果发生切换的时候,可以在从节点查询到最新的数据
- 如果从节点无法回复确认(或者确认丢失),那么master会一直阻塞等待。并且会影响后面的操作。
异步复制的特点
- 最大的特点就是效率非常高,这里的效率不是指复制很快。是指不用阻塞,发起复制之后不用等待确认回复,直接可以用了。
- 没有保证多久能复制完成,这会造成主从之间的距离比较大
实际上主从的取舍
在实际dba环境中,如果一个复制让所有节点完成后才能接受请求,这不太现实(因为距离可能很远,数据量很大,节点很多,网络原因等…)
因此,一般来说通过同步异步混合的半同步办法。这种办法可以保证至少有两个节点拥有最新的数据(恢复的时候比较好)。并且不会阻塞很长时间
- 把其中一到两个节点设置为同步复制
- 其他节点设置为异步复制
配置新的从节点
当一个空白的节点要作为slave加入集群中时,一般按照如下操作步骤
- 把该节点注册到集群,master和slave之间建立连接
- master执行mysqldump(good to have),把最近一次的全量备份发送到slave
- 并且从备份的时间点开始发送binlog
处理失效的节点
从节点失效处理策略 — 追赶试恢复
- slave查询最后一笔事务的事务id,然后连接到主节点
- 主节根据事务id,找到对应的binlog,然后发送断开连接时发生的数据变更
master节点失效 —选举新的主节点
- 发送heart-beat,确认主节点是否存活
- 在集群中选举新的主节点
- 重新配置
- 建立新主节点和从节点之间的连接
- 防止脑裂的情况
可能存在的问题
- 如果新的主节点 并未收到所有主节点的数据。(还在接受旧主节点的binlog状态中)。
- 宕机的主节点很快又上线,但他(还认为自己是主节点,没意识到改朝换代了)继续发送binlog,让其他slave进行同步
- 这时候新的主节点就会很困惑,不知道是否要接受旧主节点的binlog写数据。
- 不写,违背了数据持久化的承诺
- 写,这非常冲突
- 主节点宕机,选举出新的主节点。(新的主节点和旧的主节点之间,数据存在一定距离)
- 新主节点的自增id落后于旧的节点。但是某些中间件已经同步了旧主节点的 那部分自增id的记录
- 这会导致一种数据泄露的问题
- 脑裂
复制滞后的问题
马上读 — 好像数据丢失了
根据CAP理论,高可用性和一致性,只能选择一个。大多数分布式系统都是选择高可用性,因此会出现数据丢失的问题。
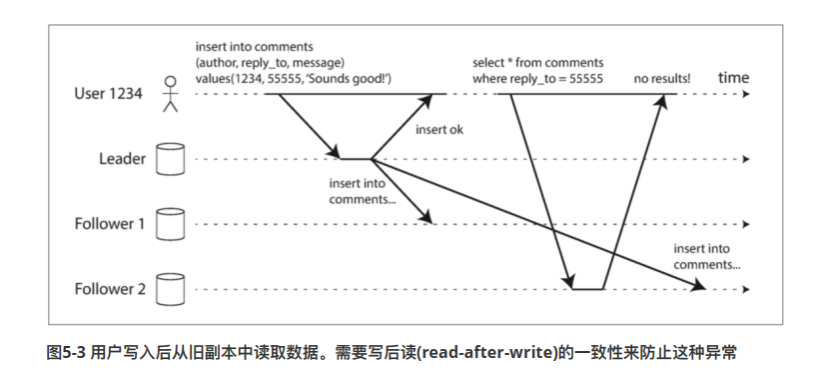
解决马上读问题,一般常用的办法。
- 如果用户访问会被修改的内容则从master节点读取;否则,从slave节点读取。
- 举个例子,在一个博客系统中,你编辑自己的文章并且发布,当然希望马上能读取,这时候我们从master节点拉自己的文章。但是读别的文章,就可以从slave上面进行读取
- 客户端保存更新操作的timeStamp,发送请求时把这个东西附送上
- 一个副本根据timeStamp读取数据,判断一下他的数据是否够新,如果不够新,就转发给下一个副本节点,从它那里取数据
单调读 — 两次读到的内容不一样
- 简单来说,第一次读,转发到某个节点上,该节点是最新的数据
- 紧接着第二次请求,但是该请求转发到另外的节点上。该节点还没完成数据同步,因此读到旧版本的数据
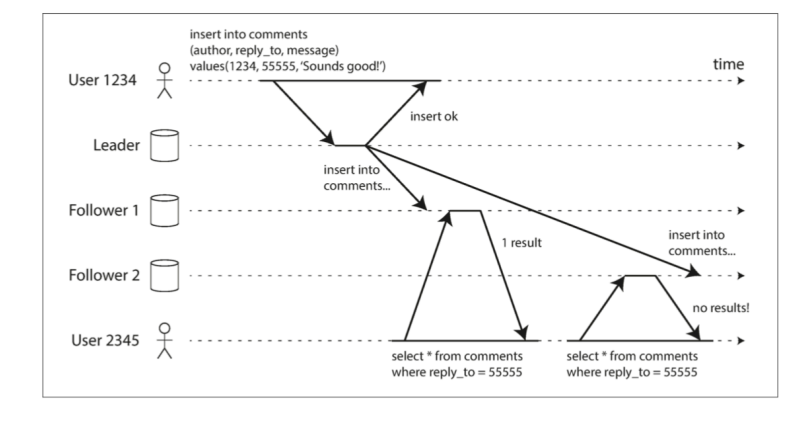
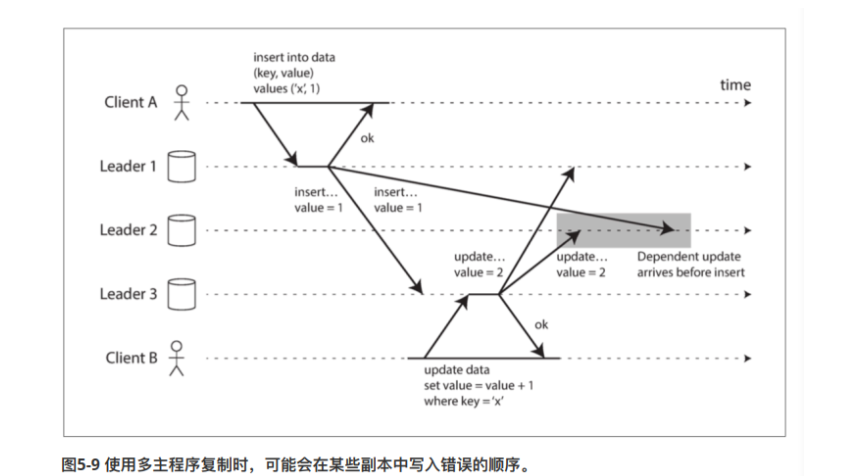
顺序写入问题
- 某些记录之间存在顺序关系
- 比如insert a,update a。这两个存在明显的顺序关系,但是可能因为网络等原因,到达从节点之间不一致什么的
目前解决这类问题的办法,好像是通过一些拓扑算法,显式跟踪事件之间的因果关系。
实际开发中
如果在开发中,不是对数据滞后带来的后果无法容忍。一般都会忽略到他们,比如说,在更新头像这服务上面,很多时候更新头像是有延迟的,一段时间后才会真的让你更新成功。
不然,如果不能忽略,上面的处理方案,都是要在应用层进行编写。这会给应用层的代码逻辑带来很大的挑战。
多主节点复制 — 数据中心
为了实现异地容灾,或者说缩短客户端和数据库的距离。通常把整个数据库集群做一个备份,每个备份作为一个数据中心。
每个数据中间内部,都是采用主从复制。数据中心之间,采用多主节点复制。
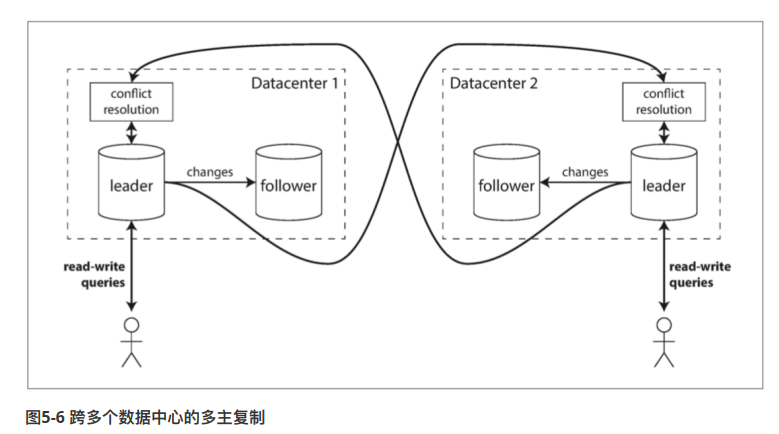
如何处理写冲突
多主从最大的问题就是容易产生写冲突。
例如,两个用户同时编辑wiki页面。他们的操作都分别路由到两个不同数据中心,这是完全合法的操作。
但是,两个数据中心进行merge的时候,则会出现冲突问题
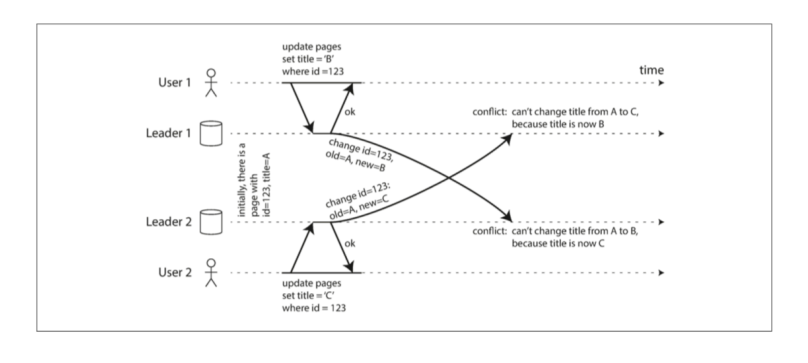
同步 和 异步 检测写冲突
如果是单主从模式下,只能有一个写,另外一个写操作会被阻塞。然而,在多主从这种架构之下,在数据中心的角度来看,每个写请求都是成功的。
因此,每次写入操作都能完成,并且冲突只能异步地,在以后才进行一次检测。
理论上,也不是不能进行同步检测。只需要像2PC一样,让一个节点出来充当monitor。但是会十分影响性能。
避免冲突
目前来说,处理写冲突的最好的方案就是避免冲突。把不同记录的修改,根据hash进行路由,这样不同数据中心之间”被修改的记录”就会交错,不会有重合部分,自然就不会有冲突
Last Write Win — LWW
每个更新操作,附带一个时间戳。数据中心之间进行收敛的时候,根据时间戳进行复制。原则是,最新的记录要覆盖之前的记录。
这样,数据中心最后会收敛到一致。
多主从的拓扑结构
常见的拓扑结构有三种(1)环形 (2)星形 (3)全连接。一般来说,越复杂的拓扑结构。稳定性越高(指的是,不会因为关键节点宕机而整个网络瘫痪)
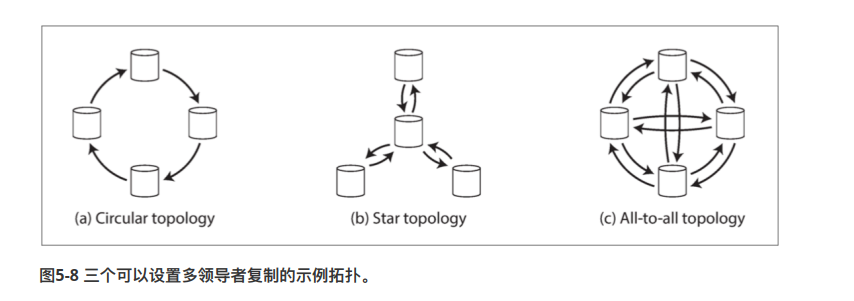
问题
- 对于环形和星形的问题,其实很简单。跟计算机网络一样,如果某个crux节点宕机了,整个服务会受到相当大的影响。
- 全连接网络其实也有很一些问题,主要是受到网络延迟的影响**(就是说,节点收到同一份binlog的时间可能是不一样的)**
1 | |
无主节点复制
一些存储系统采用不同的设计思路:选择放弃主节点,所有副本能够直接接受写请求。换句话来说,所有节点都是主节点。
有一些无主节点系统的实现,每个节点都可以直接接收客户端的写请求。但有一些实现,会有一个协调者,他来统一进行管理。
节点失效时写入数据库
写数据的过程
- 假设某个数据库系统中,有三个节点。其中一个节点宕机下线了
- 客户端直接发送写请求给到所有节点
- 假设三个节点中,只有两个恢复ack。我们就认为他就是写入成功
读数据的过程
- 当一个客户端从数据库读取数据时,它不是向一个副本发送请求。而是并行发送多个副本。
- 当客户端拿到结果后,根据投票或者版本号,来确认采用哪个副本的。
数据修复
如果某个节点中途下线了,如何让他修复数据追赶上进度?
读修复
- 当客户端从三个副本那里拿到数据之后,假设拿到数据时(版本1,版本3,版本3)。
- monitor就会觉得版本1数据落后了,因此把版本3数据往该节点写入。
反熵
- 后台有进程不断查找副本之间数据的差异
- 并且会自动进行修复
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!