MySQL基础架构 --- 一条语句是怎么执行的?
对于一个很简单的表,里面只有一个字段ID,执行下列语句时
1 | |
我们对该语句的执行过程进行,一个拆解。
MySQL的基本架构图
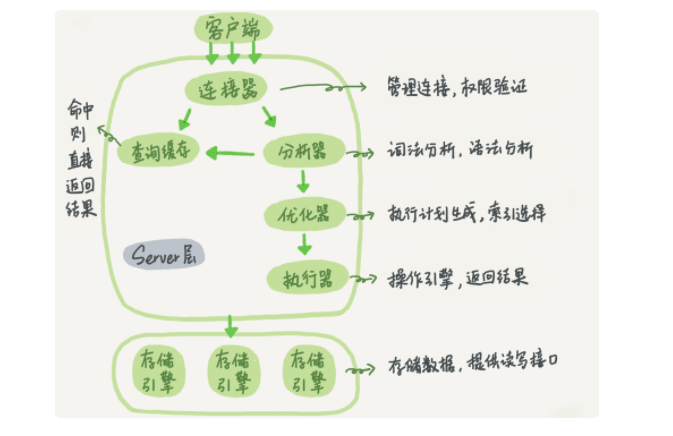
- 连接器:管理数据库连接
- 分析器:类似编译原理,进行一个SQL语法的分析,判断是否符合语义
- 优化器:进行索引的选择
- 执行器:引擎操作器,拿到结果
- 缓存: 保存之前的页,如果有就直接返回(一般mysql很少开启缓存)
- 引擎层:如何存放,并且组织数据
日志系统 一条更新语句如何完成(两阶段提交)
之前学习select流程的时候,一条查询语句的执行顺序是客户端,连接器,分析器,优化器,执行器,引擎。
update语句,跟select语句有点类似,但是又有很多区别(涉及到日志的两阶段提交)
update语句执行流程
1 | |
对于这条更新语句,select所走的所有流程,update都会走一遍,因为只有拿出该页才能对record进行一个update。
但是与查询流程不同的是,update还涉及到两个很重要的模块**redo log(重做日志)和binlog(归档日志)**。
redo log(引擎层的日志)
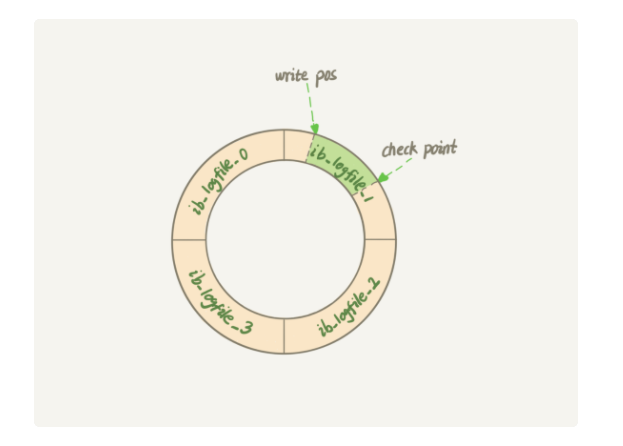
在Innodb中,redo log可以理解为一个可以循环使用的文件。为了循环使用,必须有两个指针。分别为write_pos 和 check_pos。
- write_pos:新的一条日志记录,从哪里开始记录
- check_pos:表示,循环开始的地方。如果write_pos == check_pos,代表当前文件已经写满,必须fresh当前的重做日志了
作用
- 让数据库有了对事务进行重做的能力,能把还没来得及归档的数据,通过日志重新跑一编。
binlog(server层日志)
MySQL 整体来看,其实就有两块:
- 一块是 Server 层,它主要做的是 MySQL 功能层面的事情;
- 还有一块是引擎层,负责存储相关的具体事宜。
binlog就是server层独有的日志,记录的是对某个记录的逻辑上的操作(比如,给ID=2这条记录的C字段+1)
为什么server层也要有一个日志?
- 因为,innodb不是mysql原生的存储引擎,而是作为一个插件来进行补充的。
- 因此server原生的MYISAM引擎,理所应当也要有一个日志binlog
两者区别
redo log只属于innoDB引擎;binlog是所有MySQL中server层的日志
redo log物理日志,每条记录表示在某个数据页进行了什么操作
binlog是逻辑日志,每条记录的逻辑变化(给某个字段 + n)
redo log循环写,binlog顺序写
update的两阶段提交
有了两个日志的概念,下面讲讲update语句的执行流程
- 通过执行器,取出对应的数据页
- 并且给对应的记录进行操作,再给到innoDB引擎
- 引擎拿到改写的页后,刷盘,并且把该操作写入redo log中
- 并把对应的事务ID标记为,prepare可以提交状态
- prepare之后,告知执行器,刷盘完成了。
- server层中,生成该操作的binlog,并且写入磁盘,再告知引擎
- 引擎把prepare状态改为commit
以上就是两阶段提交的全部过程。
如何让数据库恢复到半个月内的任意一秒?
场景:
1 | |
操作:
- 找到最近一次的全量备份(read-view)
- 然后重跑全量备份 到 昨天中午十二点的删表操作的binlog
为什么要有两阶段提交?
因为有了两阶段提交,数据库通过这两个日志进行crash-safe之后,一定能保证恢复的数据是自洽的。
因为恢复数据库的时候,需要重跑binlog。我们需要拿出binlog的每条记录跟redo log进行比对,看看是否commit,如果commit就执行,不然就放弃
如果没有两阶段提交
(1)先提交redo log,再提交binlog
1 | |
(2)先提交binlog,再提交redo log
1 | |
QA
1.为什么binlog没有crash-safe功能
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!