如何做数据分区
数据分区
数据分区 和 数据复制
分区通常与数据复制一起使用。也就是说,买个分区,保存在多个节点上面,同样的内容保存在多个节点上面。有利于提高系统的容错性。
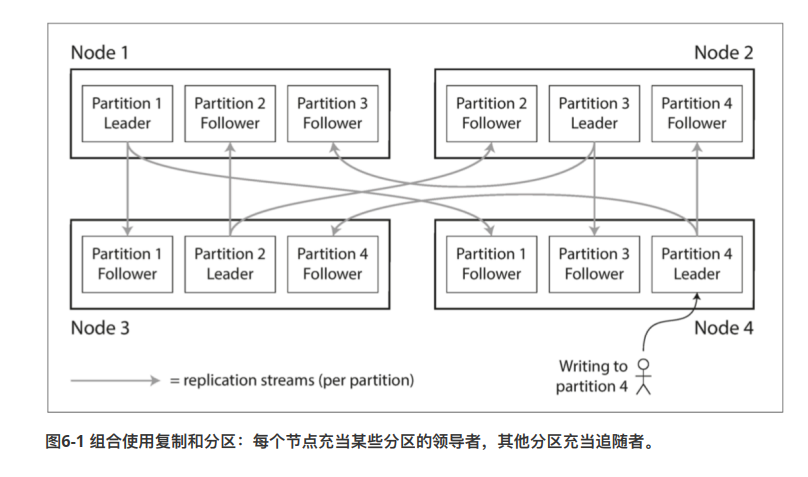
key-value 数据分区方法
面对海量数据,单库不能负载。因此我们需要分区,主要目标是把数据和查询负载均匀分布在所有节点上。
如果节点平均分布,那么理论上会扩大n倍的吞吐量。
但是如果分区策略选的不好,会出现热点倾斜的问题。
1 | |
基于关键字分区

缺点
- 比较容易出现热点倾斜,比如说靓号。这样会导致其他分区处于空闲状态,没有很好体现分区的好处
基于关键字哈希值分区
针对上述热点倾斜的问题,许多分布式系统采用了关键字哈希来进行分区。
一个好的哈希函数,可以让数据分布得比较均匀。一旦找到合适的关键字哈希,就可以为他分配一个哈希范围,然后确定分区。
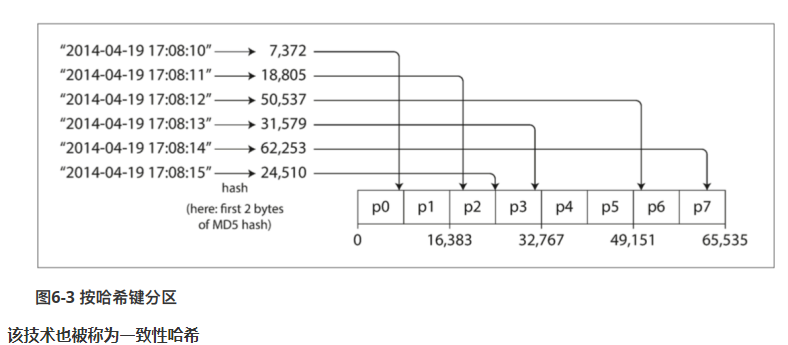
特点
- 一致性哈希拓展性比较好,很容易添加节点,或者减少节点
- 但是哈希之后,记录分散在不同的分区。原本逻辑上相邻的记录,会被映射的不同的地方,因此比较难进行范围查询
范围查询难 — 折中解决方案
- 以TDSQL为例,设计的时候,指定一个
shard_key分片键。然后,定义的所有索引都要带有这个分片键。 - 假设分片键是user_id,那么就可以对该user_id一些相关的字段作范围查询
负载倾斜的解决方案
- 如果出现热点事件,那么会导致某一个键会被大量访问,即使通过hash处理,某个键的负载也会很高
- 一般是给热点数据,加一个随机数,使他分散到不同的分区上面。
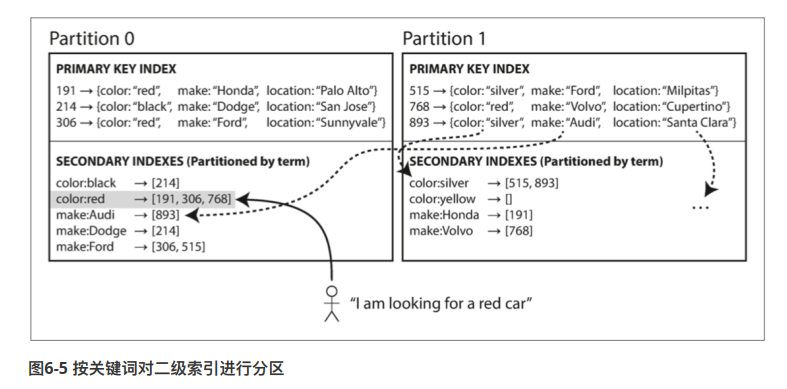
分区之后 非聚集索引如何处理
- 每个分区,维护自己分区的二级索引
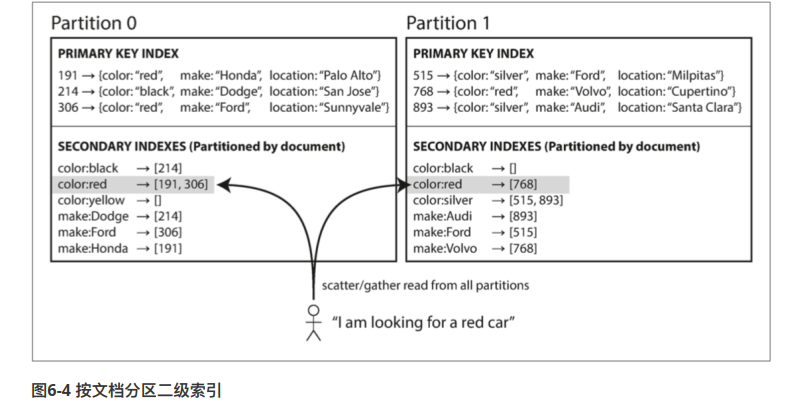
- 每个分区维护一种耳机索引(该索引是全量数据)
分区再平衡
随着时间的推移,数据库系统可能会出现某些变化:
- 查询压力增加,需要更多的CPU进行处理
- 数据规模越来越大,需要更多的磁盘进行存储
- 节点出现故障
这些变化都要求数据和请求可以从一个节点转移到另一个节点。这种方案叫做动态平衡。需要满足这些要求
- 平衡后,负载应该是要均匀的
- 平衡过程中,数据库可以正常提供服务
- 尽量使平衡过程中的数据迁移,迁移量尽可能少
动态再平衡策略
庞大分区法
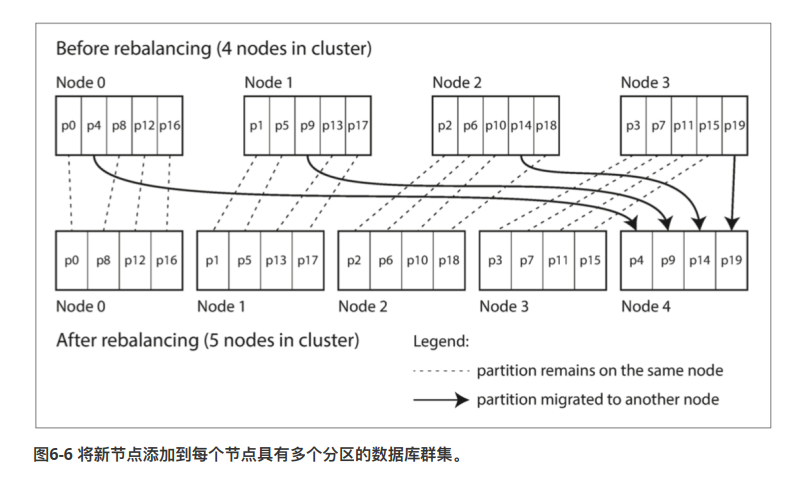
这个方案非常简单。创建远大于节点数量的分区。然后进行动态平衡的时候,比如说添加节点,我们可以从每个节点中,匀走一些分区,组成新的节点。
动态分区法
可以把它想象成B-Tree。如果某个节点太庞大就分裂成两个分区,如果太小就合并
请求路由问题
现在我们已经将数据分布到很多节点上,但是还没解决收到一个请求时,把请求转发到哪个节点。甚至,分区再平衡的时候,这个映射关系是动态变化的
类似服务发现的问题
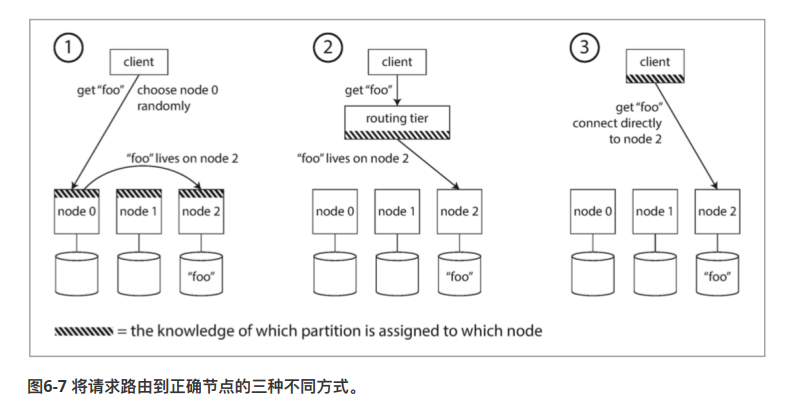
- 方案一:客户端随机转发到一个节点,如果命中则处理该请求。否则,节点转发到下一个节点
- 方案二:往上架一层,该层感知所有节点信息,负责路由。
- 方案三:客户端感知节点信息,直接转发。
不管用什么办法,核心是:做出路由决策的组件,如何感知分区之间的变化?
这是一个很有挑战的问题,让所有参与者都达成共识,否则请求会被发送到错误的节点,没有得到正确的处理。分布式系统中有专门的共识协议(理论上存在)
解决方案
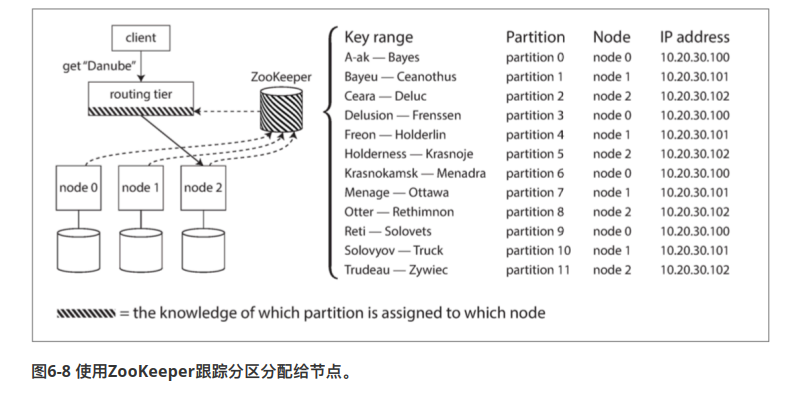
一般来说,让决策组件感知变化,会借鉴Zookeeper。
- 每个节点都向zookeeper注册自己
- 决策组件可以向zookeeper订阅信息
- 并且,如果节点发生变化,zookeeper会向所有订阅者更新信息。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!